
【ZiDongHua 之智能自动化收录关键词:中国科学院自动化研究所 强化学习 神经网络 】
AAAI 2024 | 自动化所新作速览
导读 | 日前,中国计算机学会(CCF)推荐的A类国际学术会议AAAI公布论文接收结果。AAAI(AAAI Conference on Artificial Intelligence) 由国际先进人工智能协会主办,是人工智能领域的顶级国际学术会议之一。第38届AAAI人工智能年度会议将于2024年2月在加拿大温哥华举行。本文将介绍中国科学院自动化研究所团队在AAAI 2024中录用的27篇论文(排序不分先后)。
01. 语义概念引导下的集合预测用于多样化视频描述
Set Prediction Guided by Semantic Concepts for Diverse Video Captioning
作者:卢一帆,张子琦,原春锋,李鹏,王炎,李兵,胡卫明
现有多样化描述方法使用独立的“视频-单句描述”对作为训练样本,不同描述间缺乏交互,描述集合内多样性的没有被充分挖掘。在本工作中,我们提出了基于语义概念引导集合预测(SCG-SP, Semantic-Concept-Guided Set Prediction)的多样化视频描述方法。首先,我们将视频多样化任务形式化为一个集合预测问题,使用模型直接拟合视频的人工标注的描述集合,实现集合层面的建模。随后,我们考虑了描述多样性的来源:语义概念(目标、行为、场景等)。不同的语义概念组合代表了对视觉内容的不同解读,因此我们使用语义概念引导集合预测,进一步提升生成描述的语义多样性。语义概念引导包含两方面:1)对视频中的语义概念进行检测,利用其得到语义特定的视频编码;2)增加语义概念预测的辅助任务,引入额外语义监督。我们的方法在多个视频描述数据集上取得了先进表现。

02. 基于强化学习的图像信号处理参数顺序优化方法
RL-SeqISP: Reinforcement Learning-based Sequential Optimization for Image Signal Processing
作者:孙鑫雨,赵治坤,魏莉莉,郎丛妍,蔡明轩,韩龙飞,王隽,李兵,郭宇轩
硬件图像信号处理(ISP)旨在将输入的RAW图转换为RGB图像,它由一系列处理模块组成,且每个模块都包含了许多可调的参数。目前,ISP参数大都由成像专家根据图像质量和特定任务下的性能指标进行手动调整,这一过程耗时耗力,而且会受到人类视觉主观偏好影响。此外,每个参数的变化与输出性能指标之间的关系是复杂的非线性函数,所以优化如此大量的ISP参数极具挑战性。受人类专家的序列化调优过程的启发,我们提出了一种序列化ISP参数优化模型(RL-SeqISP),它利用深度强化学习来预测不同成像应用的所有ISP参数。我们提出的模型通过融合来自图像特征空间和参数空间的信息来逐步提高图像质量。此外,为了避免ISP参数陷入局部最优,我们引入动态参数优化模块。与其他的方法相比,RL-SeqISP模型的优点及效率通过在广泛的下游任务上的综合实验得到证实。这里特别需要指出的是即使只使用10%的训练数据,我们的模型在两个视觉分析任务上也比其他SOTA方法平均高出7%的mAP。

03. 动态图片利用的多模态摘要方法
DIUSum: Dynamic Image Utilization for Multimodal Summarization
作者:肖敏,朱军楠,翟飞飞,周玉,宗成庆
已有的多模态摘要工作都在假设图片一定对摘要或多或少有帮助的前提下,结合图片信息生成摘要,而忽视了不是所有样本都可以帮助提升摘要质量的问题。因此,我们提出了一个动态图像利用框架,以动态选择用于多模态总结的图像。首先,我们提出了一个图像选择器,根据多模态特征对每个图像进行评分。该图像选择器预测图像是否有助于生成比单模输入更高质量的摘要。具体而言,我们使用自我标记方法优化图像选择器,该方法根据多模输入是否有助于生成比单模输入更高质量的摘要来定义图像的贡献。然后,在图像选择器的指导下,解码器动态地利用多模态信息生成摘要。通过这些步骤,模型可以获取对生成摘要更有效的图像信息,并为摘要提供更好的多模态信息。
通过实验结果,对图片动态利用的方法均在两个公开数据集上拿到了最好的(State of Art, SOTA)的性能。这也进一步证明了我们的初衷,即不同样本对不同模态的需求是不一样的。

图1. 模型框架
“TxtEnc”和“ImgEnc”分别代表文本和图像特征提取器。“Selc”代表图像选择器
表1 在MMSS数据集上的实验结果
04. 神经群体编码启发的连续旋转群等变网络
Continuous Rotation Group Equivariant Network Inspired by Neural Population Coding
作者:陈智强,陈阳,邹晓龙,余山
群体编码在生物神经元中是一个普遍的机制,比如海马中的‘place cell’、初级视觉皮层的方向、颜色、朝向等神经元都是通过群体编码的方式来编码信息的。钟型调谐曲线(bell-shaped tuning curve)对于神经群体编码通过离散的最优刺激来编码连续信息是至关重要的。受此启发,我们通过高斯调制将钟型的调谐曲线嵌入到离散的群等变卷积中,从而实现使用离散群卷积达到连续群等变的目的。受益于高斯调制,卷积核在几何维度上(如位置维度、方向维度)也具有平滑的梯度,这使得可以使用稀疏的带有可学习几何参数的权重来生成群等变卷积核,从而使得网络既具有竞争性的性能又具有极高的参数效率。
实验结果表明:1)在MNIST-rot上相比于之前的方法,我们的方法能够使用更少的参数(少于25%)达到极具竞争力的性能;2)尤其是在小样本学习下,我们的方法能够得到更加显著的性能提升(24%);3)同时在更多的数据集(如MNIST、CIFAR和ImageNet)和不同的网络架构上(平直网络架构和ResNet架构)都具有不错的旋转泛化能力。


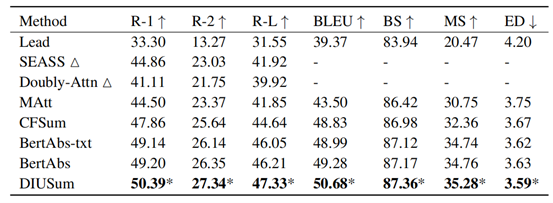
05. 从静态域到事件域的脉冲神经网络知识迁移策略
An Efficient Knowledge Transfer Strategy for Spiking Neural Networks from Static to Event Domain
作者:何翔,赵东城,李杨,申国斌,孔庆群,曾毅
脉冲神经网络 (SNN) 因为其事件驱动的优势而著称,时间上的特征使得SNN适合处理事件数据。然而事件数据往往规模较小,限制了其进一步发展。相比而言,静态的RGB数据集规模较大且更易获取。静态的图片能为事件数据提供有价值的空间信息,但由于事件数据与静态图片是两种不同的模态,它们存在着固有的域差异。
为了减小域差异,优化SNN在事件数据上的表现,我们主要从两个方面来进行解决:第一是特征分布,第二是训练策略。对于特征分布,我们设计了知识转移损失函数,其包括域对齐损失和时空正则化。域对齐损失通过减少静态图像和事件数据之间的边缘分布距离,来学习和获取域不变空间特征。时空正则化为域对齐损失提供动态调整的系数,以更好地学习数据中的时间特征。在训练策略方面,我们提出了滑动训练策略,即在训练过程中用事件数据概率性地逐步替换静态图像输入,从而平滑地减少知识转移损失的作用,使训练过程更加稳定。在三个数据集上的实验结果充分表明了所提方法的有效性。
相关代码开源在:
https://github.com/BrainCog-X/Brain-Cog/tree/main/examples/Perception_and_Learning/img_cls/transfer_for_dvs.
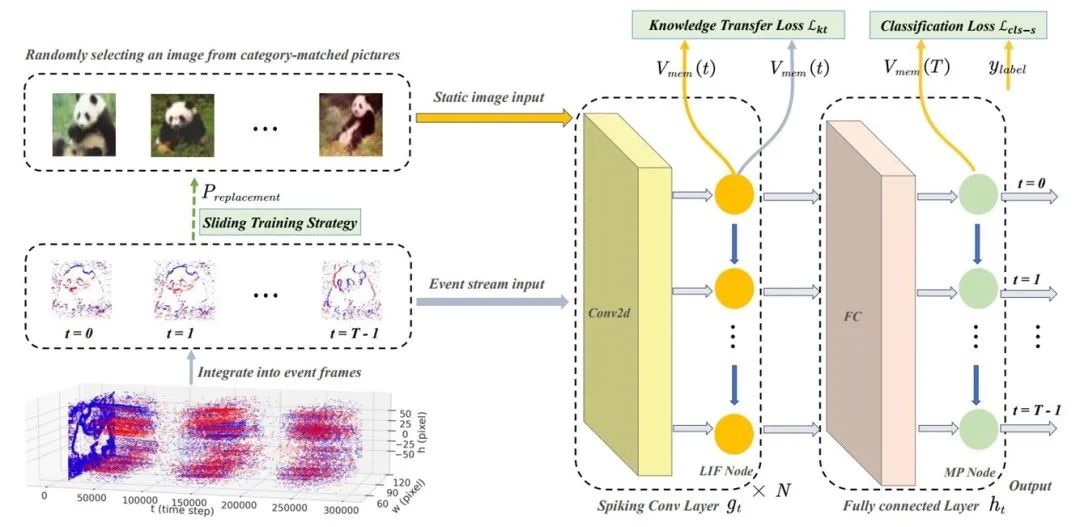
06. 弱分布检测器可以提升视觉语言提示调整的泛化性能
Weak Distribution Detectors Lead to Stronger Generalizability of Vision-Language Prompt Tuning
作者:丁昆,张好剑,于强,王颖,向世明,潘春洪
预训练视觉语言大模型包含丰富的知识,将这些模型在不同的下游任务上微调以快速解决特定领域的问题是最近的一个研究趋势。传统的微调技术在参数效率和泛化性上均存在问题。近期,基于提示调整的参数高效微调技术在图像识别、图像分割等任务中取得不错的性能。然而,提示调整技术在保持跨类别泛化性方面仍存在缺陷,即在可见类上进行提示调整后,新类上的识别性能显著下降。
考虑到未经提示调整的零样本分类器在新类上具有很好的识别性能,而提示调整的小样本分类器在可见类上识别性能更优,本研究将跨类别泛化性问题转换为分布外检测(OOD,Out-of-Distribution)问题。首先,针对零样本分类器和小样本分类器分别计算分布内得分;接着,基于这两个得分计算两个分类器各自的权重;最后,使用上述权重对两个分类器进行动态加权。本研究在理论和实验上展示了即时所使用的分布检测器的分类精度不高,仍然能促进视觉语言提示调整的跨类别泛化性。 

07. 学习如何去看:用于目标检测和相机调整的协作具身学习
Learn How to See: Collaborative Embodied Learning for Object Detection and Camera Adjusting
作者:申领东,霍春雷,许诺,韩超伟,王子辰
被动的目标检测器通常是在大规模静态数据集上训练的,往往忽视了从物体检测到图像获取的反馈。具身视觉和主动检测通过与环境互动缓解了这个问题。然而,实现主动性取决于资源密集型的数据收集和标注。为了解决这些挑战,我们提出了一个协作式的学生-教师框架。技术上,我们基于轨迹数据构建了一个replay buffer,封装了状态、动作和奖励之间的关系。此外,学生网络通过使用蕴含因果自注意力的GPT结构的序列决策路径来替代使用强化学习的决策过程。此外,教师网络基于相邻状态的差异建立了状态-奖励映射,为学生提供可靠的奖励,使其能够基于庞大的未标记的replay buffer数据自适应地调整权重。教师网络内还提出了一个简单但有效的奖励参考值,增强了其有效性和简洁性。利用灵活的replay buffer和教师-学生之间的具身协作,该框架学会在检测之前用更浅的特征和更短的推理步骤进行观察。实验证明,我们的算法在与最先进的检测器相比具有显著优势。

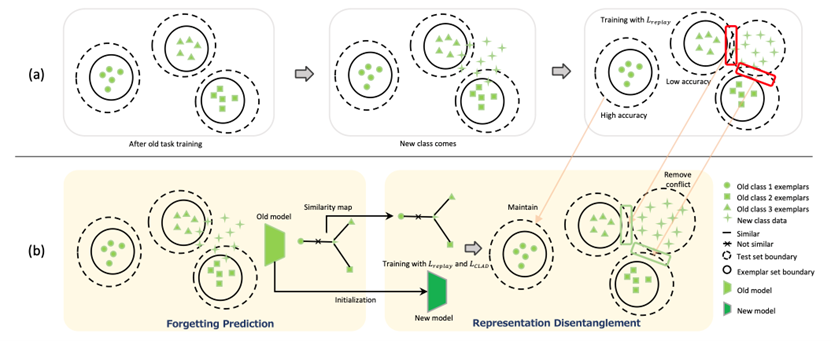
08. 对抗类别增量学习中的不平衡遗忘
Defying Imbalanced Forgetting in Class Incremental Learning
作者:许世雄,孟高峰,聂兴,尼博琳,樊彬,向世明
我们首次观察到在同一个旧任务中不同类别的准确性存在高度不平衡的现象。这个有趣的现象是在基于回放的类别增量学习(CIL)中发现的,它揭示了已学习类别的遗忘存在不平衡,因为在灾难性遗忘发生之前它们的准确性是接近的。由于CIL中依赖于平均增量准确性作为衡量标准,这种衡量标准假设同一任务中的类别准确性是相似的,因此此前的研究工作中忽视了这个现象。然而,在面对灾难性遗忘时,这个假设是无效的。进一步的实验与分析表明,这种不平衡的遗忘是因为语义上相似的旧类别和新类别之间在特征空间中存在冲突引起的。这些冲突源于基于回放的CIL方法中存在的类别不平衡。基于这些发现,我们提出了Class-Aware Disentanglement(CLAD)方法,用于预测更有可能被遗忘的旧类别并提高它们的准确性。重要的是,CLAD可以无缝地集成到现有的CIL方法中。大量的实验表明,CLAD能够稳定的改进当前的基于回放的方法,带来高达2.56%的性能提升。
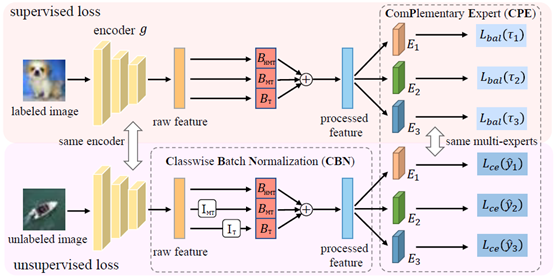
09. 基于互补专家的长尾半监督算法
Three Heads Are Better Than One: Complementary Experts for Long-Tailed Semi-supervised Learning
作者:马成丞,Ismail Elezi,邓健康,董未名,徐常胜
在长尾半监督图像分类任务中,训练集包含少量的有标注数据和大量的无标注数据,有标注子集服从长尾分布,无标注子集服从未知的类别分布,且可能与有标注子集不同。在经典的半监督算法框架FixMatch中,数据集的长尾分布会导致大量的无标注数据被误分为头部类别,而这些类别不均衡的伪标注反过来加重了模型的认知偏差(confirmation bias)问题,最终模型将大部分测试样本误分成头部类别。本文基于混合专家(Mixture-of-Experts,MoE)的思想,采用不同强度的logit adjustment同时训练三个分类头,从而保证在多种不同的无标注子集类别分布下始终可以有一个分类头能预测出准确的伪标注,保证模型特征提取器的训练效果。实验证明,本文在CIFAR-10/100和STL-10数据集上均能取得不错的分类精度。
相关链接:
https://github.com/machengcheng2016/CPE-LTSSL
10. 基于时变反演扩散模型的音乐风格迁移
Music Style Transfer with Time-Varying Inversion of Diffusion Models
作者:李思霏,张宇欣,唐帆,马重阳,董未名,徐常胜
随着扩散模型的发展,文本引导的图像风格迁移已经展示出高质量可控的结果。然而,利用文本进行多样化的音乐风格迁移面临着严峻的挑战,主要是由于可用的匹配的音频-文本数据集的有限性。音乐作为一种抽象而复杂的艺术形式,即使在同一种风格中也表现出较高复杂性,因此准确的文本描述具有挑战性。本文提出了一种能够使用最少数据有效捕捉音乐属性的音乐风格转换方法。我们引入了一种新颖的时间变化的文本反演模块,以精确捕捉不同层次的梅尔频谱特征。在推理过程中,我们提出了一种减少偏差的风格化技术,以获得稳定的风格化结果。实验结果表明,我们的方法可以转换特定乐器的风格,并结合自然声音来创作旋律。
相关链接:
https://lsfhuihuiff.github.io/MusicTI/
11. 基于复合文本监督的提示学习
Compound Text-Guided Prompt Tuning via Image-Adaptive Cues
作者:谭淏、李俊、周亦庄、万军、雷震、张祥雨
随着大规模视觉-文本预训练的出现,视觉-文本模型在下游任务中展现出强大的泛化能力。然而:1)现有的基于提示学习的微调框架需要对所有类别的文本输入进行并行化处理,当目标数据集含有大量类别时,会造成巨大的显存消耗;2)此外,现有工作需要在提示输入中包含类别名称,在处理模糊类别名时表现不佳。
为了解决这些不足,我们提出使用复合文本引导提示学习,显著减少了显存需求,并获得了更好的性能。具体而言,我们引入文本监督来约束提示向量的优化,以带来两个好处:1)在推理阶段,模型不再依赖预定义的类别名集合,实现了更灵活的提示输入;2)减少了文本端的输入数量,从而显著降低显存消耗。具体而言,我们发现复合文本监督(即基于类别的监督和基于内容的监督)十分有效,它们分别提供了类间可分性和类内多样性。此外,我们还设计了一个连接器模块来桥接文本与视觉模态,促进提示向量与视觉特征的对齐。
我们在少样本图像识别和域泛化任务上进行了广泛的实验,证明了所提出的方法以较低的训练成本实现了更优的性能。我们希望这项工作能够启发更丰富、通用的文本监督,以进一步增强提示微调在更广泛下游任务上的表现。

图1. 方法框架图
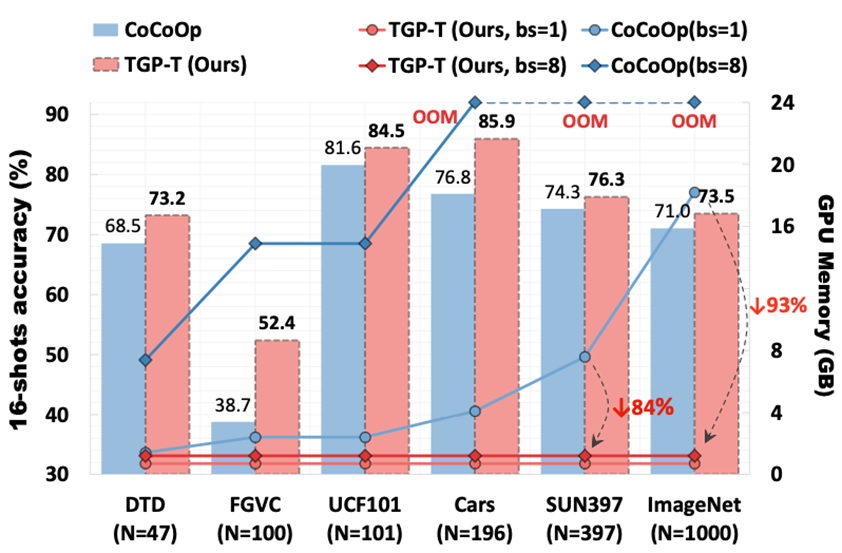
图2. 显存消耗与性能对比图
代码地址:
https://github.com/EricTan7/TGP-T
12. WaveNet:基于图谱小波的非平稳图信号处理
WaveNet: Tackling Non-Stationary Graph Signals via Graph Spectral Wavelets
作者:杨智睿,胡羽蓝,欧阳晟,刘敬宇,王书强,马喜波,Wenhan Wang,Hanjing Su,刘勇
在谱图神经网络的研究中,多项式方法在基于拉普拉斯矩阵的滤波器设计上占据主导地位。然而,由拉普拉斯矩阵析取的多项式组合在信息传递中存在一定的限制(如过度平滑),并且多数谱图神经网络采用的多项式基也会导致图谱信号高频信号的丢失。此外,本研究发现,即使增加多项式阶数也无法改变这种情况,这意味着基于多项式的模型在面对高频信号时存在一定的缺陷。为解决这些问题,本研究打破了多项式方法在谱图神经网络设计中的主导地位,并为研究人员引入了一种新的视角。首先,本研究在谱图信号上采用多分辨率分析,证明了小波对高频信号的强大拟合能力。然后,本研究利用尺度函数在图中重构谱信号。进一步,本研究还采用图像图表实验、节点分类实验以及合成玩具实验证明了所提方法在学习复杂滤波器方面的有效性、性能优越性以及细小成分捕捉能力的高效性。最后,本研究还对学习到的滤波器进行了可视化,验证了真实世界数据集的真实滤波器的复杂性。

图1. WaveNet的架构示意图。信号重构过程基于小波基,本研究利用Haar小波在图数据上进行滤波。
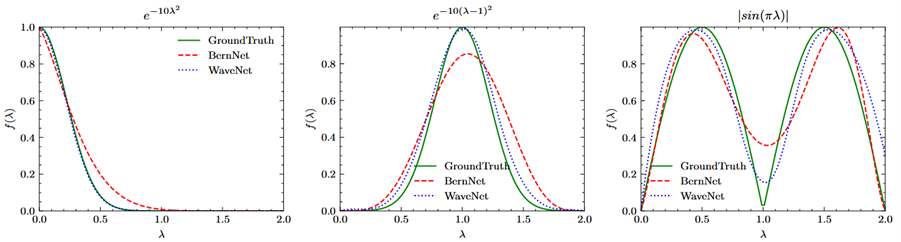
图2. BernNet和WaveNet学习的滤波器示意图。WaveNet表现出了比BernNet更好的滤波器拟合性能。
13. 基于倒角法向距离和多尺度几何特征的鲁棒点云法向估计
CMG-Net: Robust Normal Estimation for Point Clouds via Chamfer Normal Distance and Multi-scale Geometry
作者:吴应睿、赵明阳、李克强、全卫泽、于天琪、羊箭锋、贾晓红、严冬明
本文提出了一种鲁棒的高准确度点云法向估计方法。先前的方法对噪声的鲁棒性较差,难以被应用于实际场景中,主要原因为:1)直接以标注法向作为拟合目标,导致在带噪声点云上拟合目标与潜在表面不一致;2)输入尺度选取在细节保留和噪声平滑上存在矛盾。针对标注法向与潜在表面不一致的问题,本文以带噪声点云和干净点云的法向相似度为衡量标准,提出了倒角法向距离(Chamfer Normal Distance,CND)作为更合理的评价指标,并基于CND修正了网络训练的损失函数,提高了网络对噪声的鲁棒性,如图1所示。
此外,本文设计了一种基于多尺度局部特征聚合和分层几何信息融合的法向估计网络,如图2所示。
这种架构能够利用不同尺度特征的优势,更有效地捕捉复杂的几何细节,并缓解在尺度选择上的矛盾。实验证明,本文的方法在合成和真实的数据集上都取得了最佳的效果,且在噪声鲁棒性方面有较大的提升。

图1. (a) CND图示,(b) 不同方法的法向估计效果对比

图2. CMG-Net流程
论文链接:
https://arxiv.org/abs/2312.09154
代码链接:
https://github.com/YingruiWoo/CMG-Net Pytorch
14. AnomalyGPT: 基于多模态大模型的工业异常检测方法
AnomalyGPT: Detecting Industrial Anomalies Using Large Vision-Language Models
作者:古兆鹏,朱炳科,朱贵波,陈盈盈,唐明,王金桥
MiniGPT-4,LLaVA 等多模态大模型在图像理解方面展现了卓越的能力,在多种通用视觉任务中取得了显著效果,但是现有的多模态大模型缺乏特定领域知识,而且对物体中局部细节的理解较弱,这导致这些方法不能很好地完成工业异常检测任务。另一方面,大多数现有的工业异常检测方法仅预测异常分数,需要人工设定阈值以区分正常和异常样本,这限制了这些方法的实际应用场景。本文提出了一种基于多模态大模型的新型工业异常检测方法——AnomalyGPT,通过模拟异常样本的方式生成多模态训练数据,使用图像解码器为语言大模型提供图像细节语义信息,并设计了一个提示学习器,使用提示嵌入对多模态大模型进行微调。AnomalyGPT不需要手动设置阈值,可以直接判断异常是否存在并指出异常位置,可以实现多轮对话,而且可以在测试阶段利用少样本迁移到之前从未见过的新类别物体上。在仅提供一个正常样本的条件下,AnomalyGPT在 MVTec 数据集上达到了 85.5% 的准确率,94.1% 的图像级 AUC 和 95.4% 的像素级 AUC,显著地超过了现有方法的性能,在工业场景少样本和无监督场景中取得了业内最好性能。

图1. AnomalyGPT与现有的多模态大模型和工业异常检测方法的效果对比图

图2. AnomalyGPT多模态大模型框架图
论文链接:
https://arxiv.org/abs/2308.15366
项目主页链接:
https://anomalygpt.github.io
开源代码链接:
https://github.com/CASIA-IVA-Lab/AnomalyGPT
15. 基于波动性度量的大语言模型的自适应结构化剪枝
Fluctuation-based Adaptive Structured Pruning for Large Language Models
作者:安永琪、赵旭、于涛、唐明、王金桥
网络结构剪枝是解决大语言模型(LLMs)计算资源需求过大问题的有效方法。用于LLM的剪枝方法一般是无需重新训练的,以避免计算量过大。然而,现有几乎所有的无需重新训练的LLM剪枝方法都属于非结构化剪枝,需要特定硬件支持以获得真实加速。本文归纳了LLM结构化剪枝的三个关键要素:结构化剪枝度量、全局压缩结构和性能恢复,并由此提出了一种无需重新训练的LLM结构化剪枝框架——FLAP。FLAP利用波动性度量判断去除各权重组后输出特征图的可恢复性,然后归一化各层度量指标以全局搜索压缩结构,最后通过统计基准值添加额外的偏置项来恢复输出特征图。在多种语言基准测试中,FLAP的表现显著优于现有的结构化剪枝方法,包括Wanda(结构化剪枝版本)、LLM Pruner。在50%剪枝率下,FLAP的困惑度相较于现有SOTA降低了19%,零样本任务准确率比现有SOTA高1.49%,并实现了相较原始模型66%的推理加速。
论文链接:
https://arxiv.org/abs/2312.11983
代码链接:
https://github.com/CASIA-IVA-Lab/FLAP
16. 针对深度合成音频检测的自适应连续学习方法
What to Remember: Self-Adaptive Continual Learning for Audio Deepfake Detection
作者:张晓辉,易江燕,王成龙,章楚源,曾思丁,陶建华
语音合成和声音转换的迅速发展引起了重大关注,因为这种技术的潜在滥用可能性,迫切需要有效的音频深度伪造检测机制。现有的检测模型在区分已知类型的深度伪造音频方面已显示出可喜的成功,但在遇到新的攻击类型时则面临巨大的挑战。为了应对这一挑战,一种新兴且有效的方法是连续学习。在这篇论文中,我们提出了一种称为幅度权重修正(RWM)的连续学习方法,用于音频深度伪造检测。RWM的基本概念涉及将所有类别分为两组:一组是在任务中具有紧凑特征分布的类别,如真实音频;另一组是分布更离散的类别,如各种类型的假音频。这些区别通过类内余弦距离来量化,随后RWM引入针对不同数据类型的可训练梯度方向修正的机制。通过与一众主流连续学习方法进行比较,实验结果表明RWM在新知识获取和减少对已学知识的遗忘方面的优越性。此外,RWM不仅适用于音频深度伪造检测,实验结果还显示了其在图像识别等多个机器学习领域的潜在应用价值。
论文链接:
https://arxiv.org/abs/2312.09651
代码链接:
https://github.com/Cecile-hi/Radian-Weight-Modification
17. 根据颜色的低频先验评估辐射场的几何形状
Evaluate Geometry of Radiance Fields with Low-frequency Color Prior
作者:方启航,宋亚斐,李克强,申丽,吴怀宇,熊刚,薄列峰
辐射场是三维场景的一种有效表示方式,它已被广泛应用于新视角合成和三维重建中。评估重建的几何形状,即密度场,仍然是一个开放且具有挑战性的问题。这是因为物体几何形状的真值不易获得,往往需要3D扫描和各种预处理,所以许多广泛使用的数据集都没有物体几何形状的真值,这导致密度场难以评估。为此,我们提出了一种新的度量标准,即逆平均颜色残差(Inverse Mean Residual Color,IMRC),它只需物体图像就可以评估重建的密度场。其关键在于,重建的密度场越准确,计算出颜色场的频率就越低。具体地,我们设计了一种计算颜色场的方法,用低频球面谐波来逼近颜色场,并采用逼近的残差代替颜色场的频率,由此计算IMRC。IMRC越高,则密度场的几何形状越好。定性和定量的实验结果验证了所提IMRC的有效性。我们还使用IMRC对几种最先进的方法进行了基准测试,以推动未来相关研究的发展。

图1. IMRC计算流程图

图2. 新视角下渲染的图像、深度图以及颜色残差。IMRC可以正确分析重建的密度场质量
代码地址:
https://github.com/qihangGH/IMRC
18. 基于一致性与均匀性重新审视图掩码自编码器
Rethinking Graph Masked Autoencoders through Alignment and Uniformity
作者:王亮,陶翔,刘强,吴书,王亮
图自监督学习可以分为对比式方法和生成式方法。在过去几年中,对比式方法即图对比学习(GCL),在该领域中占据了主导地位。然而,最近提出的图掩码自编码器(GraphMAE)重新引起了人们对生成式方法的关注。尽管生成式方法和对比式方法都在实践中取得了成功,但它们之间的联系与差异还未被充分探讨。因此,我们首先在理论上建立了GraphMAE与GCL之间的关联,证明了GraphMAE中的节点级重构目标隐式地执行了上下文级别的GCL。基于我们的理论分析,我们进一步从表征一致性和均匀性的角度分析GraphMAE的局限性:其一致性受限于掩码策略,而均匀性并未得到严格保证。为了克服这些局限,我们提出了一致性与均匀性增强的图掩码自编码器AUG-MAE。具体来说,我们提出了一种由易到难的对抗掩码策略,以提供难以对齐的样本,从而改善表征一致性。同时,我们引入了显式的均匀性约束,以确保学习到的表征具有均匀性。在基准数据集上的实验结果证明了我们模型具有显著优势。
19. 学习用于神经辐射场人脸重演的稠密对应
Learning Dense Correspondence for NeRF-Based Face Reenactment
作者:杨嵩林,王伟,兰宇时,樊翔宇,彭勃,杨磊,董晶
人脸重演是一项具有挑战性的任务,需要建立在不同的人脸表征之间的稠密对应关系用于运动迁移。最近的研究采用了神经辐射场(NeRF)作为基础表征,进一步提高了多视图人脸重演在照片逼真度和3D一致性方面的性能。然而,由于隐式表征缺乏像基于网格的3D参数化模型(例如3DMM)的索引对齐顶点标注,因此在不同人脸NeRF之间建立稠密对应关系并非易事。尽管通过将3DMM空间与基于 NeRF 的人脸表征对齐可以实现运动控制,但由于其有限的仅面部建模和低身份保真度,这并不是最佳选择。因此,我们受到启发提出了一个问题:我们是否可以在没有3D参数模型先验的情况下学习不同人脸NeRF 表征之间的稠密对应关系?为了解决这个挑战,我们提出了一个新颖的框架,采用三平面作为基础NeRF表征 ,并将人脸三平面分解为三个组件:标准型空间三平面、身份形变和运动形变。在运动控制方面,我们的主要贡献是提出了一个平面字典模块,它将运动条件高效地映射为一组可学习的正交平面基的线性加权和。我们的框架是第一个在没有3D参数模型先验的情况下实现单图、多视角人脸重演的工作。大量实验证明,我们在精细运动控制和身份保持方面取得了比先前方法更好的结果。
相关链接:
https://songlin1998.github.io/planedict/
20. 基于多目标优化的长尾学习
Long-Tailed Learning as Multi-Objective Optimization
作者:李炜骐,吕凡,尚凡华,万亮,冯伟
现实世界中普遍存在的长尾分布(数据严重不平衡)问题通常会导致模型偏向具有足够样本的类别,对稀有类别表现不佳,针对该问题研究的方法称为长尾学习方法。长尾学习中常采用重新平衡类别的策略,但该策略面临补偿不平衡问题,即提高尾部类别的性能可能会降低头部类别的性能,反之亦然。本文认为模型学习不平衡问题源于不同类别梯度的不平衡,即在更新过程中抑制了欠学习类别的梯度贡献,或者过度补偿欠学习类别导致过拟合。为实现对各类别梯度进行理想补偿,本文将长尾学习问题构建为多目标优化问题,公平对待头部和尾部类别的贡献。为提高优化效率,提出了梯度平衡分组(GBG)策略,将具有相似梯度方向的类别聚在一起,使每次模型参数更新近似地往帕累托下降方向前进。本文提出的GBG方法使具有相似梯度方向的类别组合为更具代表性的梯度,并为尾部类别提供理想的补偿。
相关链接:
https://arxiv.org/abs/2310.20490
21. 用于文本和表格事实核查的异构图推理
Heterogeneous Graph Reasoning for Fact Checking over Texts and Tables
作者:龚海松,许伟志,吴书,刘强,王亮
本研究旨在通过对多个证据进行推理,从而预测论断的真实性。通常,这包括证据检索和真实性推理两个主要步骤。本文聚焦于后者,即对非结构化文本和结构化表格信息进行推理。过去的研究主要依赖于微调预训练语言模型或训练同质图模型。尽管它们有效,但我们认为它们未能充分探索不同结构下潜在的语义信息。为解决这一问题,我们提出了一种新颖的基于异构图的事实检查模型——HeterFC。我们的方法利用异构证据图,以单词为节点,巧妙设计的边表示不同的证据属性。通过关系图神经网络进行信息传播,促进论断和证据之间的交互。我们采用基于注意力的方法整合信息,结合语言模型生成预测。引入多任务损失函数以考虑证据检索中的潜在不准确性。在大规模事实检查数据集FEVEROUS上进行的综合实验证明了HeterFC的有效性。
22. 基于扩散语言模型的文本引导分子生成
Text-Guided Molecule Generation with Diffusion Language Model
作者:龚海松,刘强,吴书,王亮
文本引导的分子生成旨在根据文本的描述通过AI生成符合文本描述内容的分子,从而辅助可能的药物设计和研发。近年来基于SMILES分子表达的分子生成方法多依赖于自回归的生成模型。本研究指出自回归生成模型有因固定生成顺序而无法修改已生成内容的弊端,可能在分子生成领域带来缺乏对全局约束有效利用的不利影响。因此本研究提出使用扩散语言模型进行文本引导的分子生成,并提出TGM-DLM模型进行验证。TGM-DLM采用两阶段的逆扩散过程从随机噪声中生成分子,其中第一阶段以文本描述为约束生成符合文本描述的分子SMILES嵌入,第二阶段对第一阶段结果进行矫正,修正可能存在的语法错误。通过实验,TGM-DLM展现了优秀的性能,与同参数量级的采用自回归生成框架的MolT5比较,获得了3倍的准确匹配率以及分子指纹相似性指标上18%至36%的增长。
23. 基于显式接触和隐式物体相结合的单目手物交互重建
Learning Explicit Contact for Implicit Reconstruction of Hand-held Objects from Monocular Images
作者:胡俊星,张鸿文,陈泽睿,李梦成,王云龙,刘烨斌,孙哲南
基于单目RGB图像的手物交互重建是一项具有挑战性的任务。现有方法利用隐式函数可以较好地重建手持物体,但是它们没有很好地利用手物接触信息,从而导致交互重建的效果不够理想。本工作将显式的手部接触预测和隐式的物体重建相结合,以促进手物交互的重建。首先,直接从单张图像中预测三维的手物接触,通过将区域级和顶点级的图变换器以从粗到细的方式级联来获得更准确的接触预测。然后,将估计的接触信息从手部网格表面扩散到附近物体所处的三维空间,并利用扩散的接触概率构建物体的隐式神经表达,这种建模方式可以有效改善手物接触部分的重建。在多个数据集上的实验表明,本方法在取得最佳指标的同时,可以实现视觉上更加合理的手物交互重建。

图1. 本方法的整体流程图
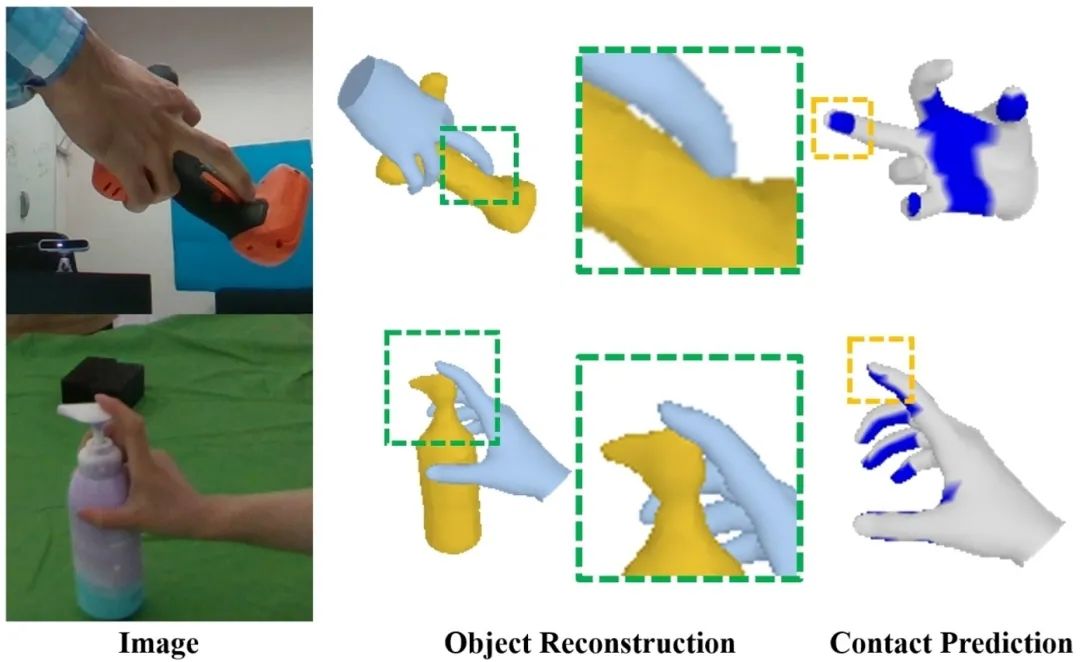
图2. 输入一张RGB 图像,本方法可以预测手-物接触的区域并以此指导手持物体的三维重建
相关链接:
https://junxinghu.github.io/projects/hoi.html
24. 动态深度路由的多任务强化学习
Not All Tasks Are Equally Difficult: Multi-Task Reinforcement Learning with Dynamic Depth Routing
作者:何金岷,李凯,臧一凡,傅浩波,付强,兴军亮,程健
多任务强化学习致力于用单一策略完成一系列不同的任务。为了通过在多个任务中共享参数来提高数据效率,一种常见的做法是将网络分割成不同的模块,并训练路由网络将这些模块重新组合成特定任务的策略。然而,现有的路由方法对所有任务都采用固定数量的模块,忽略了难度不同的任务通常需要不同数量的知识。我们提出了一种动态深度路由(D2R)框架,它可以选择性地跳过某些中间模块,从而灵活地为每个任务选择不同的模块数量。在此框架下,我们进一步引入了ResRouting方法,以解决离策略训练过程中行为策略和目标策略之间路由路径不一致的问题。此外,我们还设计了一种自动路由平衡机制,以鼓励在不干扰已掌握任务路由的情况下,继续探索未掌握任务的路由。我们在机械臂操作环境Meta-World中进行了广泛的实验,结果表明与MTRL基准算法相比,D2R在采样效率和最终性能方面都有显著提高。
25. 合作型多智能体强化学习的内在动作趋势一致性
Intrinsic Action Tendency Consistency for Cooperative Multi-Agent Reinforcement Learning
作者:张峻凯,张一帆,张希,臧一凡,程健
在合作型多智能体系统中,集中训练分散执行算法(CTDE)仍存在智能体高效合作的挑战。我们分析认为智能体之间的动作策略分歧是影响其训练效率的一个重要因素,这导致算法需要大量的训练样本来训练智能体的团队共识。这种分歧源于CTDE算法的信用分配过程缺乏足够的团队共识相关的奖励指导信号。为了解决这个问题,我们提出了合作型多智能体强化学习的内在动作趋势一致性算法。我们利用动作模型使得邻居智能体能够预测中心智能体的动作趋势。通过动作趋势的预测计算我们设计了一个合作型内在奖励,它鼓励将中心智能体与邻居智能体的动作趋势相匹配。除此之外我们通过理论分析建立了RA-CTDE与CTDE的等价性,证明了CTDE的训练过程可以用每个agent的独立目标来实现。在此基础上,我们提出了一种结合内在奖励和CTDE的新方法。我们在SMAC和GRF基准环境中对具有挑战性的任务进行了大量实验,性能提升证明了我们的方法的有效性。
26. 针对高效掩码图像建模的块感知样本选择
Patch-Aware Sample Selection for Efficient Masked Image Modeling
作者:诸葛正阳,王家兴,李勇,包勇军,王培松,程健
尽管样本选择在传统的监督学习中可以通过提取最具重要性的子数据集来有效减少训练成本,但由于样本级别的重要性赋分和图像块级别的预训练模式存在一定差异,将样本选择用于掩码图像建模(MIM)的加速仍然存在挑战。我们首先构建了在MIM预训练中进行样本选择的基本框架,并发现其存在严重的性能下降的问题。我们认为该问题主要归因于两个因素:随机的掩码策略和简单的平均函数。因此我们提出了块感知的样本选择方法(PASS),其中包括一个低成本的动态训练掩码预测器 (DTMP) 和加权选择得分 (WSS)。DTMP始终保持对样本中的复杂区域进行掩码,确保相对准确和公平的样本重要性得分。WSS利用图像块级别的差异来增强重要性得分。广泛的下游任务实验显示了PASS在加速MIM预训练方面的有效性。PASS在各种数据集、不同的MIM方法和各类任务中都展现出了优越的性能。例如,PASS在仅使用37%的训练数据预算的同时,在ImageNet-1K上维持了和标准MAE相当的性能,并实现了约1.7倍的训练加速。
27. 基于智能体拓扑的多智能体策略梯度算法
TAPE: Leveraging Agent Topology for Cooperative Multi-Agent Policy Gradient
作者:娄行舟,张俊格,Timothy J. Norman,黄凯奇,杜雅丽
多智能体策略梯度(Multi-Agent Policy Gradient,MAPG)近年来取得了显著的进展。然而,在最先进的MAPG方法中,集中式评论家仍然面临着中心化-去中心化不匹配(Centralized-Decentralized Mismatch,CDM)的问题,这意味着一些智能体的次优行为会影响其他智能体的策略学习。虽然使用个体评论家进行策略更新可以避免这个问题,但它们会严重限制智能体之间的合作。为了解决这个问题,我们提出了一个智能体拓扑框架,该框架决定其他智能体是否应该在策略梯度中被考虑,并在促进合作和减轻CDM问题之间实现折衷。智能体拓扑允许智能体使用联合效用作为学习目标,而不是集中评论家的全局效用或个体评论家的局部效用。
为构建智能体拓扑,我们研究了多种随机图模型。我们为随机和确定性MAPG方法都提出了基于拓扑的多智能体策略梯度(Topology-based multi-Agent Policy gradiEnt,TAPE)。我们从理论上证明了随机TAPE的策略提升定理,并为智能体之间合作能力的提升提供了理论解释。在几个基准测试中的实验结果显示,智能体拓扑分别能够促进智能体之间的合作或减轻CDM问题以提高TAPE的性能。最后,我们还进行了多个消融研究并提出了一个启发式图搜索算法,以展示智能体拓扑的有效性。



评论排行