
【ZiDongHua创新自科文收录关键词:MathWorks 机器学习 AutoML 运营一体自动化 MATLAB Simulink】
利用 MATLAB 和 Simulink 实现机器学习开发运营一体自动化
随着越来越多的组织依赖机器学习应用来实现核心业务功能,许多组织正在更深入地研究这些应用的完整生命周期。他们已将关注触角从最初的机器学习模型开发和部署,延伸到了持续监控和更新。输入数据的变化可能会降低模型的预测或分类准确度。但及时地进行再训练和模型评估,有助于构建更好的模型,并做出更准确的决策。 对于机器学习操作 (ML Ops),在持续反馈循环(图 1)中,开发领域的规划、设计、构建和测试活动与运营领域的部署、操作和监控活动息息相关。许多数据科学团队均已开始实现 ML Ops 周期各环节(例如部署和操作)的自动化。

图 1. ML Ops 周期。 但是,实现该周期的完全自动化还需要执行其他步骤:监控和评估模型性能,将该评估的结果纳入性能更好的模型中,然后重新部署新模型。实现这种自动化大有裨益,让数据科学家们能够花更多的时间设计有用的 ML 解决方案,而花较少的时间进行 IT 管理和处理繁琐易错的手动任务。 为了说明如何在 MATLAB® 和 Simu ® 中使用基于模型的设计来自动执行 ML Ops 过程,我们实现了虚构的城市交通系统预测性维护应用。组织需要采用一种方法来规划其电动巴士车队电池的维护或更换,以免电池在途中面临出现故障的风险。 这款应用包括一个机器学习模型,该模型使用电池荷电状态 (SOC)、电流和其他测量数据来预测电池的健康状态 (SOH)。其他组件包括一个应用服务器,用于大规模运行机器学习模型;一个漂移检测组件,用于将观察到的数据与训练数据进行比较,以确定需要再训练的时间;以及一个高保真电池物理模型,可用于自动标注观察到的数据。 最后一个组件是高保真物理模型。对许多组织来说,这是实现完全自动化过程中缺失的一个环节。没有它,就需要有人来审查观察到的数据并应用标签;有了它,这个基本步骤乃至整个 ML Ops 周期便可实现自动化。 ▼ 构建模型以生成电池数据和自动标注 在开始训练机器学习模型,用于预测电池的健康状态之前,我们首先需要有数据。在一些情况下,组织可能拥有大量从运行中的真实系统收集的数据。而在另一些情况下,数据必须通过仿真来生成,包括用于我们的虚构交通系统的数据。 为了生成用于该交通网络的电池系统的训练数据,我们使用 Simu 和 Simscape™ 创建了两个基于物理的模型。第一个模型运用了电和热领域的动态特性,可生成真实的原始传感器测量数据,包括电流、电压、温度和 SOC(图 2)。第二个模型可根据电池的估计容量和内阻(源自第一个模型生成的测量数据)计算 SOH。正是因为这第二个模型,我们才能自动标注观察到的数据,并大大减少人为干预再训练循环的需求。
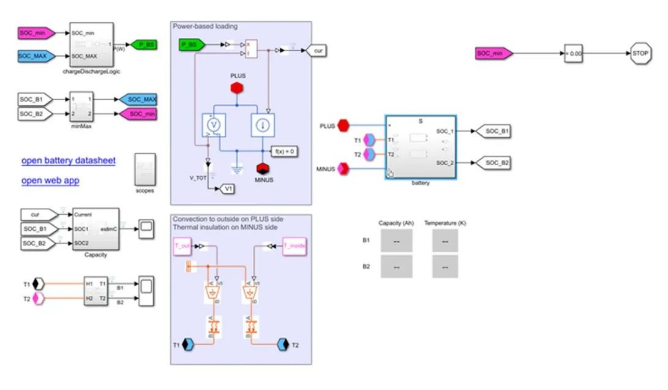
图 2. 基于物理的 Simu 电池模型,用于生成原始传感器测量数据。 通过对各电池应用独立的老化配置,并改变第一个模型的输入环境温度,我们为一个大型车队创建了历史数据集,该数据集适用于训练我们的预测性维护机器学习模型。 ▼ 构建和部署 ML 模型 有了训练数据之后,我们便将注意力转向了 ML 模型。我们使用了诊断特征设计器(点击“阅读原文”获取 App)来探索原始测量数据,提取多域特征,并选择具有最佳状态指标的特征集。鉴于我们的目标是实现整个周期自动化,我们也需要实现模型选择和训练自动化。为此,我们创建了一个称为 AutoML 的组件。该组件通过 Statistics and Machine Learning Toolbox™ 内置在 MATLAB 中,专用于根据一组给定的训练数据自动寻找最佳机器学习模型和最佳超参数。AutoML 组件也是从以下周期开始的:基于原始训练数据和我们的特征集生成初始机器学习模型。 除了支持向量机,AutoML 组件还用于训练和评估线性回归模型、高斯过程回归模型、提升决策树集成、随机森林,以及全连接前馈神经网络(图 3)。AutoML 组件使用 MATLAB Parallel Server™,通过同时训练和评估多个模型来加速这一过程。

<p style="margin: 8px 0px; padding: 0px; outline: 0px; max-width: 100%; box-sizing: border-box !important; overflow-wrap: break-word !important; clear: both; min-height: 1em; color: rgb(34, 34, 34); font-family: system-ui, -apple-system, MacSystemFont, " helvetica="" neue",="" "pingfang="" sc",="" "hiragino="" sans="" gb",="" "microsoft="" yahei="" ui",="" yahei",="" arial,="" sans-serif;="" font-size:="" 17px;="" font-style:="" normal;="" font-variant-ligatures:="" font-variant-caps:="" font-weight:="" 400;="" letter-spacing:="" 0.544px;="" orphans:="" 2;="" text-indent:="" 0px;="" text-transform:="" none;="" white-space:="" widows:="" word-spacing:="" -webkit-text-stroke-width:="" background-color:="" rgb(255,="" 255,="" 255);="" text-decoration-thickness:="" initial;="" text-decoration-style:="" text-decoration-color:="" text-align:="" center;"="">
图 3. 动画显示 AutoML 进程在评估各种模型和超参数选项时生成的结果。 当 AutoML 进程完成后,我们便使用 MATLAB Production Server™ 将最佳模型部署到了我们的本地生产环境中。 ▼ 识别并处理数据漂移 在许多机器学习问题中,都存在着一种隐式假设,那就是用于训练模型的数据完全代表着整个特征空间的底层分布。换句话说,假设数据分布不变。实际上,情况并非总是如此。例如,在我们的电动巴士应用中,我们可能已经基于车辆将在一定温度范围内运行这一假设训练了我们的模型。但在实际生产环境中,我们发现,巴士经常以高于这一范围的温度运行。数据的这种变化称为漂移。随着漂移的增加,模型预测的准确度往往会降低。因此,数据科学家经常需要检测数据随时间的推移而发生的变化并做出反应,这通常是通过训练新模型来实现的。 这里,我们应当区分概念漂移和数据漂移。对于机器学习,概念漂移是指观察到的特征和标签或响应的联合概率随时间的推移而发生的变化。在生产环境中,将概念漂移用于机器学习模型可能相当困难,因为特征值和响应值需要同时已知。因此,许多组织都关注的是另一个最佳选择,即数据漂移,也就是说仅限观察到的特征而非标签的分布变化。这就是我们所采用的方法。 我们开发了一个用于检测漂移的 MATLAB 应用,可将新观察到的数据中的值与模型训练集中的值进行比较。 在生产环境中,该应用从 Apache® Kafka 流中近乎实时地读取观察到的数据,并使用 MATLAB 函数进行电池健康预测,该函数使用我们的机器学习模型处理观察到的数据(图 4)。这一 MATLAB 函数是我们使用 Streaming Data work for MATLAB Production Server 框架开发的,后者使我们能够轻松地从处理文件中的历史数据转为处理 Kafka 流中的实时数据。该框架通过一系列迭代来处理流数据,因为并非整个流都纳入内存中。每次迭代分为四个步骤:从流中读取一批观察到的数据,加载模型,做以预测并将其写入输出流,然后根据需要保存下一次迭代所需的任何数据。每批数据的大小要跨越足够长的时间间隔,以确保提取的特征所捕获的电池特性足以用于实现有效的 SOH 预测。
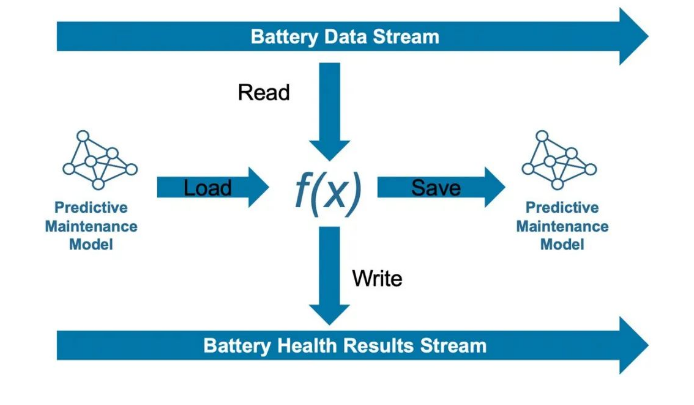
图 4. 使用数据流的预测性维护模型。 值得一提的是,即使漂移检测应用确定观察到的数据已发生了重大变化,这也不一定就意味着机器学习模型已经过时。该应用通过在整个基于物理的 SOH 模型中传播新数据来获得新观察到的数据的响应值(或标签)。在获得这些值(或标签)之前,它无法确定模型是否过时。此时,该应用可以将来自基于物理的模型的响应值与来自机器学习模型的响应值进行比较;如果这些值发生显著变化,则应使用新数据调用 AutoML 组件,并自动创建针对当前来自车队的数据进行了优化的新机器学习模型。 您一定会问,既然我们可以先通过仿真来估计电池的健康状态,为什么还需要使用机器学习模型来预测呢?答案是,ML 模型可以近乎实时地生成预测结果,其速度可能比使用基于物理的仿真快得多。 ▼ 可扩展可广泛适用的架构 我们已将用于实现 ML Ops 自动化的架构设计为可水平扩展。预测和监控组件都在 MATLAB Production Server 上运行,而模型训练在 MATLAB Parallel Server 上完成(图 5)。该架构也具有广泛的适用性。虽然我们主要以电动巴士的预测性维护和漂移检测为例,但该架构可以轻松地适用于其他应用和用例。例如,基于物理的 Simu 模型可以用在 MATLAB 中开发的数值模型代替。同样,我们所用的许多现成组件,例如用于数据流传输的 Apache Kafka,以及用于控制板框架的 Grafana,都可以用其他云原生服务代替。
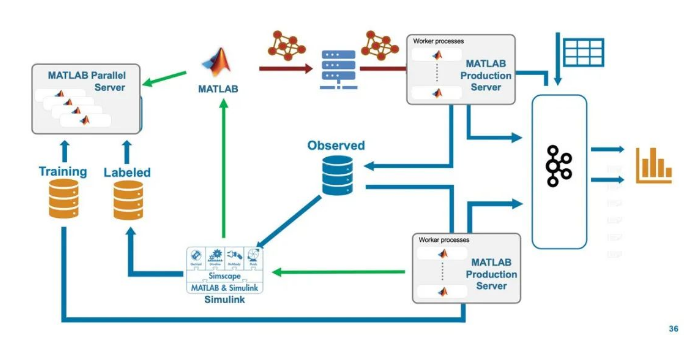
图 5. 用于实现 ML Ops 自动化的水平可扩展架构。 使用现成组件让我们能够专注于架构,而不是实现细节,就好像完全自动化的 ML Ops 周期使数据科学家能够专注于机器学习解决方案设计,而不是 IT 管理细节。
◆◆◆◆




评论排行