
【ZiDongHua 之 创新自科文:生物信息学 清华大学 、清华大学自动化系、人工智能 、神经网络、 深度神经网络模型、 多面神经元 】
清华大学自动化系汪小我团队合作提出自动归纳基因调控序列编码模式的神经网络解释方法
近日,清华大学自动化系汪小我团队与美国斯坦福大学统计系王永雄团队合作提出自动归纳基因调控序列编码模式的神经网络解释方法。该方法针对广泛应用于基因调控序列研究的卷积神经网络(CNN)模型,通过剖析神经网络中的多面神经元机制(multifaceted neuron),开发了神经网络解释算法(NeuronMotif),实现了从神经元中自动归纳和提取转录因子结合位点等关键序列模式(Motif)及其组合、次序、间距等基因调控序列编码规则。该方法能够帮助研究者更加深入地理解基因调控编码规律,同时为神经网络模型的解释提供了新手段。
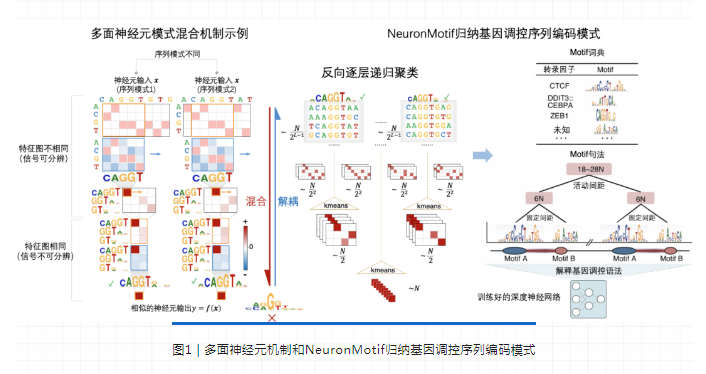
该研究发现,CNN解释困难的一个主要原因在于深层神经元大多都是“多面神经元”(multifaceted neuron)。这种神经元能够同时被多种不同序列模式激活,直接对这些混合模式进行可视化往往只能获得难以被人理解的结果。通过深入分析,该研究发现CNN中的最大池化结构是导致深层神经元识别多种序列模式的关键原因。具有不同模式的序列特征在被输入到神经网络以后,会逐层计算得到每一层网络对应的特征图(feature map),这些特征图在通过最大池化层后会丢失单碱基精度空间分辨率,导致输出的特征图变得高度相似,难以对这些混合模式进行解耦。
针对多面神经元问题及其形成机制,研究团队提出了Neuron Motif方法,该方法首先基于蒙特卡洛采样和遗传算法得到大量能充分激活神经元的序列集合,然后计算这些序列在神经网络各层的特征图,并通过反向逐层聚类的方式分离不同序列模式所对应的特征图,将具有不同模式的序列划分到不同的子集中,最终通过对每个子集的可视化获得易于理解的序列模式特征。在此基础上,该方法构建了基于结构化语法树的自动化知识提取方法,从数据中自动归纳转录因子结合位点序列模式、组合模式、间距、次序等调控序列语法规则。
NeuronMotif归纳提取的调控序列语法规则能够得到文献和多种生物组学数据的支撑和验证。通过对人类基因组数据的学习,NeuronMotif发现了数百种序列模式,与JASPAR数据库中的已知转录因子motif序列模式高度匹配;通过NeuronMotif获取的深层神经元语法规则与多种细胞/组织中的ATAC-seqfootprinting模式高度匹配,并得到了基因表达数据(RNA-seq)的支持;序列模式的组合和排布等规律在跨物种基因组序列上具有显著的序列保守性。
综上所述,NeuronMotif为我们提供了一种解读深度神经网络模型中深层神经元识别模式的新方法。此外,NeuronMotif的解释结果还可用于人工神经网络的诊断和改进,帮助降低神经网络调参的困难。借助该方法,我们可以通过神经网络的训练和解释,从数据中获取可供人类专家理解的知识,帮助我们更加深入地理解胚胎发育、疾病发生等生物过程中的基因调控规律,并为基因治疗等应用中定制化逆向构造人工基因调控序列提供支撑。
研究成果以“NeuronMotif: 通过深度神经网络的逐层解耦破译基因顺式调控编码”(NeuronMotif: Deciphering cis-regulatory codes by -wise demixing of deep neural networks)为题发表在《美国科学院院刊》(PNAS)上。
清华大学自动化系博士后魏征为本文的第一作者,清华大学自动化系汪小我教授和美国斯坦福大学统计系王永雄教授为本文的共同通讯作者。清华大学李衍达教授、张学工教授、江瑞教授、魏磊助理研究员、花奎博士,斯坦福大学博士后马士宁也对本文作出了重要贡献。该研究得到了国家自然科学基金、国家重点研发计划、清华大学国强研究院、北京智源人工智能研究院等的资助。
论文链接(点击文末“阅读原文”):
https://www.pnas.org/doi/10.1073/pnas.2216698120



评论排行