
NeurIPS 2023 | 自动化所新作速览!
【ZiDongHua 之自动化学院派收录关键词: 自动化所 机器学习 计算神经】
NeurIPS 2023 | 自动化所新作速览!
导读 | NeurIPS全称神经信息处理系统大会(Conference on Neural Information Processing Systems),是机器学习和计算神经科学领域的顶级国际会议。本期将介绍自动化所团队在NeurIPS 2023中收录的18篇论文(排序不分先后),更多接收论文将在下一期推出!
01. 基于ODE的无模型强化学习方法用于POMDPs
ODE-based Recurrent Model-free Reinforcement Learning for POMDPs
作者:赵烜乐,张笃振,韩立元,张铁林,徐波
神经常微分方程(ODEs)被广泛认可为建模物理机制的标准,有助于在未知的物理或生物环境中进行近似推断。在部分可观测的环境中,如何从原始观察中推断不可见信息是困扰智能体的一大挑战。通过使用具有紧凑上下文的循环策略,基于上下文的强化学习提供了一种灵活的方式,从历史转换中提取不可观察的信息。为了帮助智能体提取更多与动态相关的信息,我们提出了一种新颖的基于ODE的循环模型,结合无模型强化学习框架,以解决部分可观察的马尔可夫决策过程。我们通过部分可观察的连续控制和元强化学习任务实验证明了方法的有效性。此外,由于ODE能够建模不规则采样的时间序列,因此本研究提出的方法对不规则观测具有鲁棒性。
02. 脉冲驱动Transformer
Spike-driven Transformer
作者:姚满、胡珈魁、周昭坤、袁粒、田永鸿、徐波、李国齐
本文提出了首个脉冲驱动Transformer(Spike-driven Transformer),整个网络中只有稀疏加法。所提出的Spike-driven Transformer具有四个独特性质:(1)事件驱动,当Transformer的输入为零时不触发计算;(2)二进制脉冲通信,所有与脉冲矩阵相关的矩阵乘法都可以转化为稀疏加法;(3)所设计的自注意力机制在token和通道维度上都具有线性复杂度;(4)脉冲形式的Query、Key、Value矩阵之间的运算为掩码和加法。总之,所提出的网络中只有稀疏加法运算。为实现这一目标,本文设计了一种新颖的脉冲驱动自注意力(Spike-Driven Self-Attention, SDSA)算子,算子中仅利用掩码和加法进行运算,而不进行任何乘法,因此其能耗比原始自注意力算子低87.2倍。此外,为确保网络中所有神经元间传递的信号为二进制脉冲,本文重新排列了网络中所有的残差连接。实验结果表明,Spike-driven Transformer在ImageNet-1K上可以达到77.1%的 top-1精度,这是SNN领域内的最佳结果。
论文链接:
https://arxiv.org/abs/2307.01694
代码链接:
https://github.com/BICLab/Spike-Driven-Transformer
03. 动态组合模型来应对数据分布的变化
OneNet: Enhancing Time Series Forecasting Models under Concept Drift by Online Ensembling
作者:张一帆,文青松,王雪,陈纬奇,张彰,王亮,金榕,谭铁牛
概念漂移(concept drift)是时序数据常见的一个问题,即未来的数据展现出不同于过去的模式。在这些情况下,从头重新训练模型可能会非常耗时。因此,在线训练深度预测模型,通过增量更新预测模型来捕捉环境中不断变化的动态是非常必要的。本文提出了OneNet,其思想十分简单,采用了两个不同的模型,一个模型专注于建模时间维度上的相关性,另一个模型则专注于建模跨变量之间的依赖关系。这两个模型都在训练过程中使用相同的训练数据进行独立训练。在测试时,OneNet将强化学习方法引入传统的在线凸规划框架中,允许动态调整权重以线性组合两个模型。这样,OneNet可以同时利用这两种模型的优势,既能处理概念漂移,又能提高预测精度。
04. 揭示分子表示学习的神经尺度率
Uncovering Neural Scaling Laws of Molecular Representation Learning
作者:陈丁硕,朱彦樵,张介宇,杜沅岂,李志勋,刘强,吴书,王亮
近年来,分子表示学习(MRL)被证实可以有效助力药物和材料发现的多种下游任务,例如分子虚拟筛选和逆向设计。其中,以模型设计为导向的研究受到研究者们的广泛关注,但从数据的视角出发,分子的数量和质量如何影响分子表示学习还是一个开放性的问题。
本文我们以数据为中心的角度深入研究了MRL的神经尺度率,其中涉及了四个关键维度:(1)数据模态,(2)数据集分割方式,(3)预训练的干预,以及(4)模型容量。我们的研究证实了数据量和分子表示学习性能在这些维度上均满足幂律关系。此外,我们揭示了提高MRL学习效率的潜在途径。为了提高现有的幂律学习效率,我们将七种主流的数据修剪策略应用于分子数据并对其性能进行了基准测试。本工作强调了以数据为中心探究MRL的重要性,并强调了未来相关研究的可能方向。
05. 图结构学习基准库
GSLB: The Graph Structure Learning Benchmark
作者:李志勋,王亮,孙鑫,罗逸凡,朱彦樵,陈丁硕,罗颖韬,周相鑫,刘强,吴书,王亮,Jeffrey Xu Yu
本篇论文提出了首个图结构学习基准库(GSLB),其包含16个图结构学习算法和20个常用的图数据集。在本文中,我们从有效性,鲁棒性,复杂度三个维度系统地研究了图结构学习的性质。本文在节点级别和图级别任务中全面地评估现有图结构学习方法,分析他们在鲁棒学习当中的效果,以及对各算法的复杂度进行了研究。并且,为了促进可复现研究,我们开发了一个易于使用的库来对不同的图结构学习算法进行训练、评估和可视化。我们的大量实验结果显示了图结构学习的能力,并且解释了其在不同场景的任务中的潜在优势,为后续的研究提供了见解和思路。
相关链接:
https://github.com/GSL-Benchmark/GSLB
06. 回波超越点云:在多模态数据融合中释放雷达原始数据的潜力
Echoes Beyond Points: Unleashing the Power of Raw Radar Data in Multi-modality Fusion
作者:刘洋、王峰、王乃岩、张兆翔
毫米波雷达,由于其低廉的成本以及对恶劣天气的强鲁棒性,如今已成为自动驾驶系统中必备的传感器组件。然而,由于毫米波雷达产生的点云十分系数,加之方位角和仰角分辨率较差,因此基于雷达的检测算法性能通常表现不佳。此外,为了减少虚警目标,毫米波点云的生成算法只保留了峰值信号,但这对于深度融合的使用可能是次优的。在本文中,我们提出了一种名为 EchoFusion 的新方法来跳过现有的雷达信号处理流程,直接将雷达原始数据与其他传感器相结合。具体来说,我们在鸟瞰图 (BEV)空间以一种新的融合范式将雷达中获取的频谱特征与其他传感器融合。通过这种方法,我们的方法可以利用来自雷达回波的丰富的距离和速度信息和图像中丰富的语义信息,进而在RADIal数据集上超越了所有现有的方法,并达到了接近激光雷达的性能。Camera-Ready版本的论文以及代码将很快公开。
文章链接:
https://arxiv.org/pdf/2307.16532.pdf
07. SheetCopilot: 借助大语言模型让软件生产力更上一层楼
SheetCopilot: Bringing Software Productivity to the Next Level through Large Language Models
作者:李鸿鑫,苏靖然,陈韫韬,李青,张兆翔
本文作者提出了一种利用语言模型实现复杂软件操控的全新框架——SheetCopilot,并在典型办公软件Excel和GoogleSheets上进行测试。本工作将表格操控的核心功能抽象为一组虚拟 API,用于生成解决方案,作为 LLM 与软件之间交互的桥梁。为了实现高效闭环控制,SheetCopilot 根据表格状态规划每一个步骤,且借助软件错误反馈进行回溯。考虑到语言模型的输入窗口有限,每次规划都从外置知识库中提取候选API的文档,既降低输入处理用时,又提升了成功率。本文还提出一个高质量评测基准,涉及表格操作的几乎所有典型任务(公式、制图、透视表、排序筛选等)。
实验结果显示,SheetCopilot仅需约10 步组合操作即可在上千行数十列的多张表格中快速完成任务。以GPT-4 为后端模型时,SheetCopilot符合任务要求的解决方案占比最高且效率最优,GPT-3.5-Turbo紧随其后,Claude最次但也接近 GPT-3.5-Turbo。与将用户指令翻译成晦涩的VBA 代码并在Excel上执行的方法对比,SheetCopilot不仅取得了出色的成功率,生成的解决方案也通俗易懂。这意味着 SheetCopilot让不会编程的用户能以日常交流的方式指挥计算机完成繁杂的工作。
项目主页:
https://sheetcopilot.github.io/
文章链接:
http://arxiv.org/abs/2305.19308
08. 预训练视觉Transformer的新方法——重建丢弃位置 (DropPos)
DropPos: Pre-Training Vision Transformers by Reconstructing Dropped Positions
作者:王淏辰,樊峻菘,王玉玺,宋开友,王彤,张兆翔
视觉Transformer对输入图像块的顺序非常不敏感,因此亟需一种能够增强视觉转换器位置感知能力的预训练模式。为了解决这个问题,我们提出了DropPos,旨在重建在模型前向过程中随机丢弃的位置。DropPos的设计十分简单:首先,在标准的前向过程中,我们随机丢弃大量的位置编码;然后使模型仅根据视觉外观,对每个图像块的实际位置进行预测。该任务被建模为一个简单的分类任务。为了避免平凡解,我们只保留了部分可见图像块,从而增加了这项代理任务的难度。此外,考虑到没有必要重建视觉外观相似的不同图像块的精确位置的情况,我们提出了位置平滑和注意重建策略来松弛这一分类问题。在广泛的下游测试中,DropPos的表现优于有监督的预训练,并与最先进的自监督替代方法相比取得了具有竞争力的结果。这表明,像 DropPos这样显示鼓励空间推理能力,确实有助于提高视觉Transformer的位置感知能力。
09. 基于多模态查询的开放世界目标检测
Multi-modal Queried Object Detection in the Wild
作者:许逸凡,张梦丹,傅朝友,陈珮娴,杨小汕,李珂,徐常胜
我们提出了基于多模态查询的目标检测(MQ-Det),首个同时支持文本描述和视觉示例查询的开放世界目标检测器。MQ-Det是一种高效的架构和预训练策略设计,可以同时利用高泛化性的文本描述和高细粒度的视觉示例来对图像中的目标进行查询检测,即多模态查询。MQ-Det将视觉示例查询整合到现有的基于语言查询的检测器中,并提出了一种即插即用的门控感知器模块来将视觉信息插入文本描述。为了解决冻结检测器带来的学习惰性问题,我们提出了一种以视觉为条件的掩码语言预测策略。MQ-Det的简单而有效的架构和训练策略设计与目前大多数基于语言查询的目标检测器兼容,因此具备广泛的适用性。实验结果表明,多模态查询能够大幅度推动开放世界目标检测。例如,MQ-Det通过多模态查询在基准数据集LVIS上将目前最先进的开集检测器GLIP提升了约7.8% AP,而无需进行任何下游微调;同时,其将13个小样本下游任务平均提高了6.3% AP。完成以上这些提升仅需要在GLIP基础上进行额外的3%的调制训练时间。
图片
论文链接:
https://arxiv.org/abs/2305.18980
代码链接:
https://github.com/YifanXu74/MQ-Det
10. 基于全局指导视频解码器的连续非自回归视频生成方法
GLOBER: Coherent Non-autoregressive Video Generation via GLOBal Guided Video DecodER
作者:孙铭真,王卫宁,秦子涵,孙家辉,陈思涵,刘静
视频生成需要同时具备全局一致性和局部真实性。本文提出了一种新颖的非自回归方法 GLOBER,首先生成全局特征以获取综合性的全局引导,然后基于全局特征合成视频帧以生成连贯的视频。具体而言,我们提出了一个视频自编码器,其中视频编码器将视频编码成全局特征,而建立在扩散模型上的视频解码器以非自回归方式解码全局特征并合成视频帧。为了实现最大的灵活性,我们的视频解码器通过标准化的帧索引来解码时间信息,从而能够自由合成任意子视频片段。此外,我们引入了一种新颖的对抗损失,以提高合成视频帧之间的全局一致性和局部真实性。最后,我们采用基于扩散的视频生成器来拟合视频编码器输出的全局特征的分布,从而执行视频生成任务。大量实验证明了我们提出的方法的有效性和高效性,且本方法在多个基准数据集中取得了新的最优性能。
图片
相关链接:
http://arxiv.org/abs/2309.13274
11. 一种面向复杂时空因果关系的多模态视频跟踪评估基准
A Multi-modal Global Instance Tracking Benchmark (MGIT): Better Locating Target in Complex Spatio-temporal and Causal Relationship
作者:胡世宇,张岱凌,武美奇,丰效坤,李旭宸,赵鑫,黄凯奇
因果推理是人类决策中的重要能力之一,如人类在观看长时视频时可以准确定位复杂场景中的目标位置。然而,目前算法仍缺乏这种能力,现有跟踪算法虽然可以在短视频序列中持续定位目标,但在高挑战性的长视频序列中却缺乏鲁棒性。为评估智能体长时因果推理能力,本文构建了一种面向复杂时空因果关系的多模态视频跟踪评估基准MGIT,主要创新如下:(1)构建了一个长时视频文本双模态数据集,该数据包含150段总计203万帧的长视频序列,单段时长为现有基准的5-22倍;此外,每段视频均包含一套参考人类认知结构的层级化多粒度语义标签,总计7.8万词。(2)设计了一套多模态跟踪任务评测机制并对现有算法进行评估。实验结果表明现有跟踪算法缺乏长文本处理能力和模态对齐能力,无法进行长时因果推理,与人类的跟踪能力仍有较大差距。综上,本工作提供了高质量的实验环境和评测系统,能帮助研究者从多模态的视角去理解视频推理能力,并为算法的设计和评估提供支持。
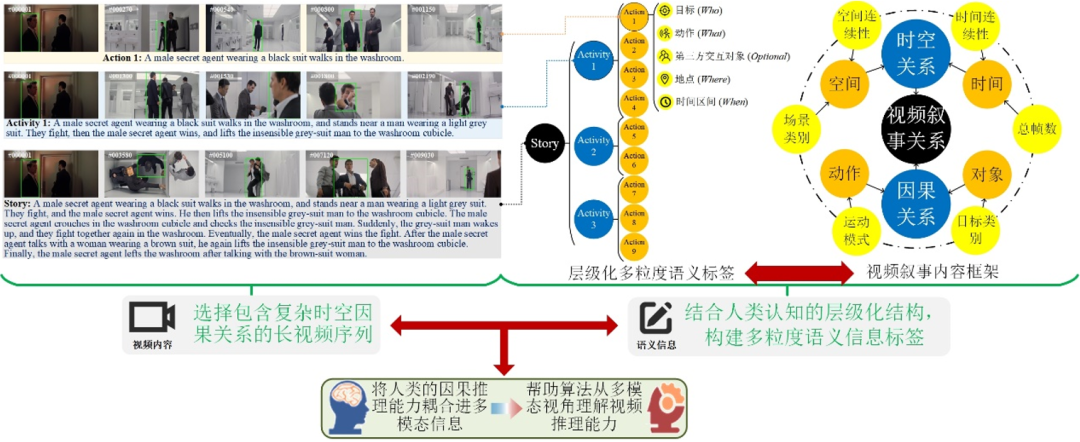
图1. 多模态单目标跟踪基准MGIT构建框架
12. 基于自动分组机制的高效合作型多智能体强化学习
Automatic Grouping for Ef?cient Cooperative Multi-Agent Reinforcement Learning
作者:臧一凡,何金岷,李凯,傅浩波,付强,兴军亮,程健
自然系统中常见的分组现象对于提高团队合作效率而言至关重要。本文提出一种分组学习的多智能体强化学习方法GoMARL,在没有任何先验知识的条件下学习自动分组来实现智能体之间的高效合作。不同于直接学习联合动作价值和个体动作价值之间复杂关系的方法,本文以小组作为桥梁建模智能体之间的关联,通过鼓励小组内和小组间的配合来提高整个团队的工作效率。具体而言,本文将联合动作价值分解为小组价值的组合,指导智能体以更细粒度的方式改进策略。GoMARL运用一种自动分组机制来生成动态组别和相应的小组动作价值,并进一步提出一种用于策略学习的分层控制,驱动同一组中的智能体学习相似的策略,不同组的智能体学习多样化的策略。本文在星际微操任务和谷歌足球场景的实验中验证了GoMARL的高效性,并通过消融实验和组件分析展示分组在提升算法性能方面的重要性。

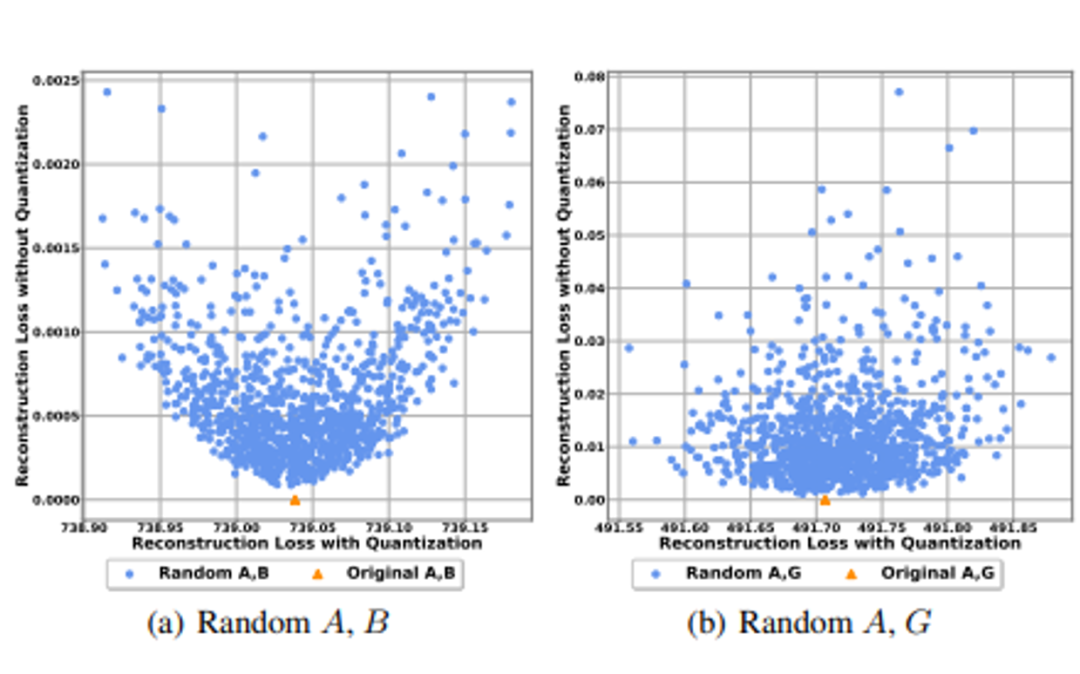
13. 面向高效准确Winograd卷积的全量化方法
Towards Efficient and Accurate Winograd Convolution via Full Quantization
作者:陈天奇,许伟翔,陈维汉,王培松,程健
Winograd算法是一种通过域变换来减少计算量的快速卷积实现。通过对Winograd卷积量化,降低其计算精度,可以进一步加速卷积神经网络,但这同样面临性能损失。针对这一问题,本文通过实验发现量化会导致Winograd变换过程的不一致性,并提出以输出对齐为监督信号对变换矩阵统一优化。另外,本文首次对Winograd的域变换过程进行全量化,并通过实验和理论分析发现量化瓶颈在于输出变换过程。本文因此提出了一种可分解的量化系数,该方法更好的兼顾了硬件友好和量化损失。
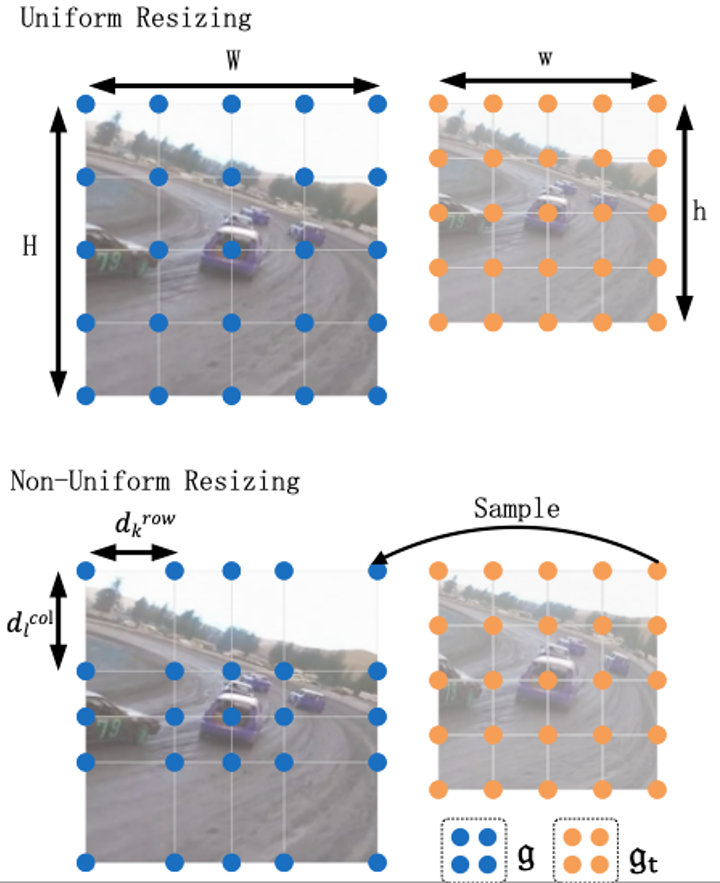
14. ZoomTrack:用于高效视觉跟踪的目标感知非均匀尺寸调整
ZoomTrack : Target-aware Non-uniform Resizing for Efficient Visual Tracking
作者:寇宇同,高晋,李椋,王刚,胡卫明,王以政,李兵
最近,由于输入尺寸更小或特征提取骨干更轻,Transformer使面向速度的跟踪器能够以高速接近最先进(SOTA)的性能,尽管它们仍然大大落后于相应的面向性能的版本。在本文中,我们证明了在较小输入尺寸的基础上实现高速跟踪的同时缩小甚至抹平这一性能差距是可能的。为此,我们非均匀地调整了裁剪图像的大小,使其输入尺寸更小,而目标更可能出现的区域的分辨率却更高,反之亦然。由此可以解决两难的问题:既要关注更大的视野,又要在较小的输入尺寸下保留更多的目标原始信息。我们的非均匀尺寸调整可以通过二次编程(QP)有效解决,并自然地集成到大多数基于剪裁的局部跟踪器中。在五个具有挑战性的数据集上对两种Transformer跟踪器(即 OSTrack 和 TransT)进行的综合实验表明,我们的方法具有一致的性能提升。特别是,将我们的方法应用于面向速度的 OSTrack 版本,在 TNL2K 上的 AUC 甚至比面向性能的对应版本高出 0.6%,同时运行速度提高了 50%,节省了 55% 以上的 MAC。
15. 基于上下文物体和关系学习的3D指代目标检测
Exploiting Contextual Objects and Relations for 3D Visual Grounding
作者:杨力,原春锋,张子琦,祁仲昂,许龑,刘伟,单瀛,李兵,杨伟平,胡卫明
3D指代目标检测是根据自然语言输入从三维场景中识别出视觉目标的任务。这项任务对于使机器人能够理解并与真实环境交互起着至关重要的作用。然而,由于需要捕获三维上下文信息才能从复杂的三维场景中分辨出目标物体,这项任务极具挑战性。同时,缺乏上下文物体和关系的标注进一步加剧了困难。在本文中,我们提出了一种新颖的检测模型 CORE-3DVG,通过对上下文物体和关系进行显式的学习来应对这些挑战。我们的方法通过三个连续的模块化网络来实现3D指代目标检测,包括一个文本引导的物体检测网络、一个关系匹配网络和一个目标推理网络。在训练过程中,我们引入了伪标签自生成策略和弱监督方法,以建立对无标注的上下文物体和关系的显式学习。所提出的技术通过对上下文物体和关系的学习,使推理网络能够更好地关注到三维场景中所指代目标。我们在具有挑战性的Nr3D、Sr3D和ScanRefer数据集上验证了我们的方法,取得了最先进的性能。
16. Bullying10K: 一个大规模神经形态数据集用于隐私保护的暴力识别
Bullying10K: A Large-Scale neuromorphic Dataset towards Privacy-Preserving Bullying Recognition
作者:董一廷,李杨,赵东城,申国斌,曾毅
日常生活中暴力行为的普遍性对个人的身体和精神健康构成了重大威胁。在公共场所使用监控摄像头已被证明在主动地阻止和预防此类事件中是有效的。但由于其广泛部署,出现了关于隐私侵犯的担忧。为了解决这个问题,我们利用动态视觉传感器(DVS)摄像头来检测暴力事件并保护隐私,因为它捕捉像素亮度的变化,而不是静态图像。我们构建了Bullying10K数据集,包括来自现实生活场景的各种动作、复杂的运动和遮挡。它为评估不同任务提供了三个基准:动作识别、时间动作定位和姿态估计。Bullying10K通过提供10,000个事件段,总共120亿次事件和255GB的数据,平衡了暴力检测和个人隐私的保护,并对神经形态数据集提出了挑战,将成为训练和开发保护隐私的视频系统的宝贵资源。Bullying10K为这些领域的创新方法开辟了新的可能性。
17. ALIM: 针对噪声部分标签学习调整标签重要性机制
ALIM: Adjusting Label Importance Mechanism for Noisy Partial Label Learning
作者:徐名宇,连政,冯磊,刘斌,陶建华
噪声部分标签学习(噪声PLL)是弱监督学习的一个重要分支。与 PLL 中的真实标签必须隐藏在候选标签集中不同,噪声 PLL 放宽了这一限制,并允许真实标签可能不在候选标签集中。为了解决这个具有挑战性的问题,大多数现有工作尝试检测噪声样本并估计每个噪声样本的真实标签。然而,检测错误是不可避免的。这些错误会在训练过程中累积并持续影响模型优化。为此,我们提出了一种具有理论解释的噪声 PLL 的新颖框架,称为“调整标签重要性机制(ALIM)”。它的目的是通过权衡初始候选集和模型输出来减少检测错误的负面影响。ALIM 是一种插件策略,可以与现有 PLL 方法集成。多个基准数据集上的实验结果表明,我们的方法可以在噪声 PLL 上实现最先进的性能。
18.VRA:针对分布外检测的变分修饰激活方法
VRA: Variational Rectified Activation for Out-of-distribution Detection
作者:徐名宇,连政,刘斌,陶建华
分布外 (OOD) 检测对于在开放世界中构建可靠的机器学习系统至关重要。研究人员提出了各种策略来减少模型对 OOD 数据的过度自信。其中,ReAct是处理模型过度自信的典型且有效的技术,它截断高激活以增加分布内和OOD之间的差距。尽管其结果很有希望,但这种技术是最好的选择吗?为了回答这个问题,我们利用变分方法来寻找最优操作,并验证了 OOD 检测中抑制异常低和高激活以及放大中间激活的必要性,而不是像 ReAct 那样只关注高激活。这促使我们提出一种名为“变分修饰激活(VRA)”的新技术,该技术使用分段函数模拟这些抑制和放大操作。多个基准数据集的实验结果表明,我们的方法优于现有的事后策略。同时,VRA兼容不同的评分函数和网络架构。
欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。
我要收藏
点个赞吧
转发分享

微信"扫一扫",分享转发
咨询详情:如需咨询文中涉及的相关产品或解决方案详情,请加微信:ZiDongHuaX 。
微信联盟:机器学习微信群、计算神经微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 解密英特尔酷睿处理器(系列1)



微信联盟:机器学习微信群、计算神经微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 解密英特尔酷睿处理器(系列1)





的人")

评论排行