
SLeM:机器学习自动化的一种实现方法 | NSR封面文章
【ZiDongHua 之自动化学院派收录关键词:机器学习 人工智能 大模型 】
SLeM:机器学习自动化的一种实现方法 | NSR封面文章
《国家科学评论》(National Science Review,NSR) 最近发表了由西安交通大学数学与统计学院徐宗本院士、束俊副教授、孟德宇教授撰写的观点文章:Simulating Learning Methodology (SLeM): An Approach to Machine Learning Automation。
这篇文章介绍了课题组提出的基于“模拟学习方法论”(SLeM)的机器学习新型范式和执行框架,特别介绍了课题组发展的SLeM基础理论与算法体系。这一理论框架为机器学习自动化提供了一个可行的实现途径。该文将作为封面文章收录于NSR“机器学习自动化”专题。

人工智能的发展及其广泛应用面临越来越复杂的场景,这对人工智能从数据到学习再到应用的整个环节都提出了新的挑战。然而现有的以机器学习为代表的人工智能技术在数据样本、学习过程、环境任务等层面高度依赖人工预设,造成“人工”决定“智能”的现状,难以满足现实问题中通常呈现的数据少/概念多、适用模型/算法依问题变化、开放环境/动态任务等本质特性,这些问题已对现有机器学习体系带来了严峻挑战。
针对以上问题,一个自然的解决途径是实现减少人工干预的自主智能方法,提高机器智能对动态开放环境和复杂多变任务的自适应学习能力,即实现所谓的机器学习自动化(Machine Learning Automation, Auto6ML),可以概括为以下六个“自”的任务目标:
数据/样本层面:样本自生成,数据自选择;
模型/算法层面:模型自构建,算法自设计;
环境/任务层面:任务自切换,环境自适应。
具体来说,一是实现数据自动化生成与筛选,能够根据目标任务需要或少量元数据(标准、高质量数据)的引导,实现训练数据或标记的自动生成,以及从海量非高质量数据中自动选择对学习目标有所增益而剔除对其有所损害的样本;二是实现模型/算法自动化构建与设计,能够根据目标任务需要自动解析完成任务所需的“功能块”,并以最优方式加以组装形成所需的深度网络架构,或者自动调节网络重要的“功能块”,能够根据问题(数据)自适应设定误差项和正则项等优化目标,自动学习机器学习模型训练算法的运算规则与算法超参数等;三是实现机器学习技术能够处理复杂多变任务、适应动态开放环境,能够使用统一的模型框架完成复杂多变任务的自适应学习, 能够持续从动态环境中学习,可以不断扩展自身的能力并提高可靠性,能够自适应地完成新任务。
实现以上研究目标涉及对机器学习过程中的数据(采集、生成、选择)、模型(学习机架构、损失函数)、算法等要素的调控和设计。这些要素的设计可以理解为对机器学习各个环节所涉及超参的有效设置,即机器学习的学习方法论学习。
基于此,文章介绍了题为“模拟学习方法论”(SLeM)的机器学习范式和执行框架,给出学习任务、学习方法的严格定义,进而把学习方法论建模成从学习任务到学习方法的映射,并使用SLeM元学习机来模拟实现这一映射。
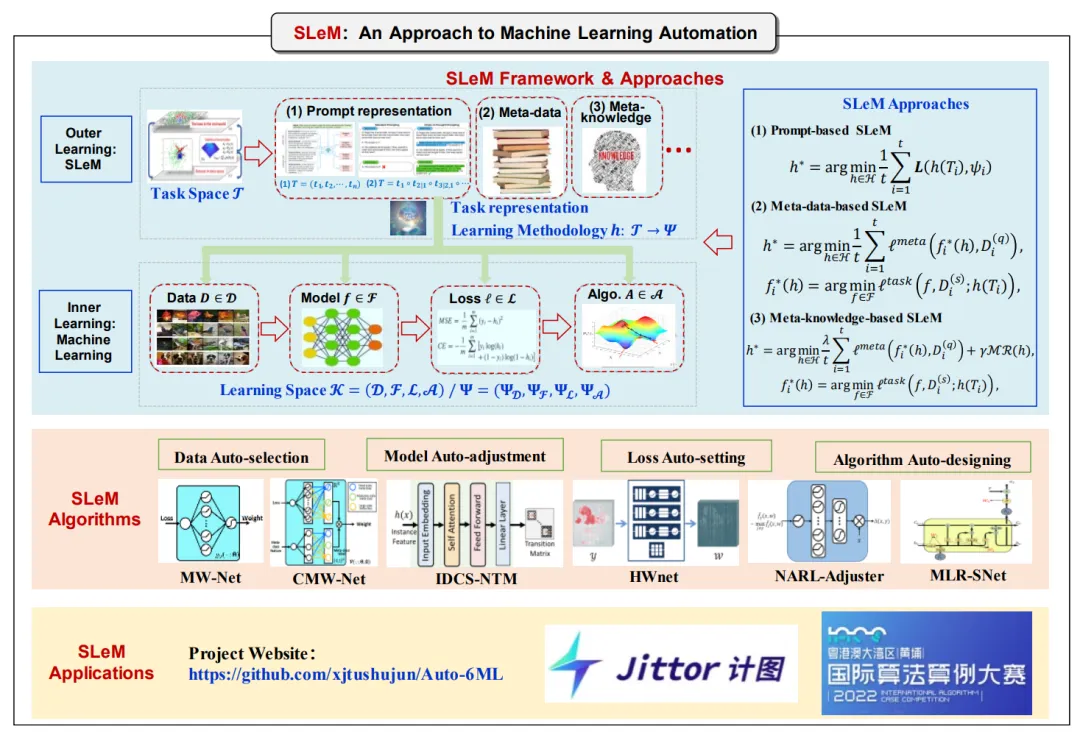
通过从学习任务层次提炼与抽取这一元学习机,可实现对数据、模型、损失、算法等机器学习要素针对变化任务的自动化设计和调控,从而为机器学习自动化提供一个可行的实现途径。
文中还介绍了三种SLeM的实现方法,以及课题组研究并实践的机器学习自动化算法簇,展现了该SLeM框架在解决实际问题上的有效性。
最后,文章指出了SLeM未来值得的研究方向:
适应更加复杂的自动化问题/场景的SLeM方法。现有的SLeM方法仅实现了机器学习各个要素的自动化,这与Auto6ML的目标还有很大差距。特别是,在SLeM的学习过程中,仍然需要大量的人为干预和选择。实现具备更强自动化能力且能够适应更加复杂的自动化问题/场景的SLeM方法,依然是未来研究中的一个重要课题。
无限维函数空间上的学习理论/跨任务泛化(迁移)理论。学习方法论学习本质上是函数空间上的学习问题,需要构建在无限维函数空间上的学习理论,以精确揭示SLeM的内在机理;SLeM学习理论揭示了影响学习方法论迁移的要素,为处理实际应用中的多样任务和动态环境提供理论基础。
建立与其他技术(如大模型)之间的联系。大模型及上下文学习技术通过一种“蛮力出奇迹”的方式实现惊人的任务泛化能力,与学习方法论的任务泛化能力密切相关,建立它们之间的联系,在理论上解释大模型的任务泛化能力,探索能够轻量化地实现具备大模型能力的计算模式,对未来研究具有重要价值。
我要收藏
点个赞吧
转发分享

微信"扫一扫",分享转发
咨询详情:如需咨询文中涉及的相关产品或解决方案详情,请加微信:ZiDongHuaX 。
微信联盟:人工智能微信群、大模型微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 查看各品牌在细分领域的定位宣传语


微信联盟:人工智能微信群、大模型微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 查看各品牌在细分领域的定位宣传语




担任班主任|哈尔滨工业大学2025年将新增全国首个自主智能系统院士特色班")
,打造大湾区首个仿生机器人“全栈技术竞技大赛”")


评论排行