
极佳科技朱政博士解读「世界模型」趋势:从语言智能到空间智能|智源2025十大趋势
【ZiDongHua之“自动化学院派”收录关键词:】
极佳科技朱政博士解读「世界模型」趋势:从语言智能到空间智能|智源2025十大趋势
近日,北京智源人工智能研究院发布“2025十大AI技术趋势”,根据行业技术及应用热点,评选出AI4Science、具身智能、原生多模态大模型、Scaling Law扩展、世界模型、合成数据、推理优化、Agentic AI、AI超级应用、AI安全十大AI趋势。
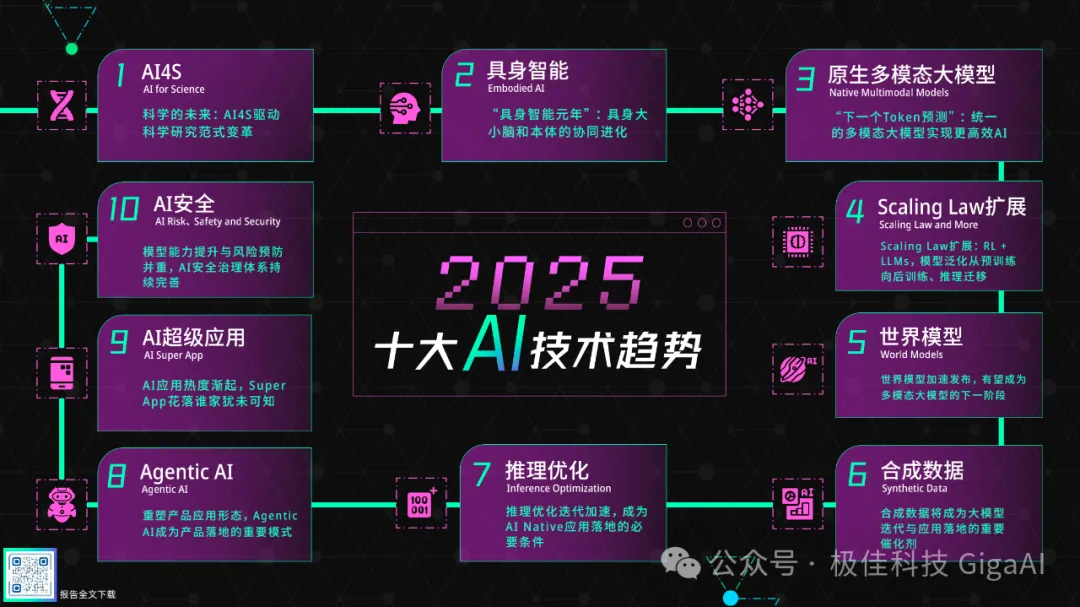
在发布会上,极佳科技联合创始人&首席科学家朱政博士发表题为《世界模型:从语言智能到空间智能》的演讲,对世界模型的发展趋势进行了进行了深入分析和点评,以下是分享全文,enjoy~

人工智能的发展历程
朱政博士首先回顾了人工智能的发展历史,是一个从解决封闭域问题走向解决开放域问题,从感知走向认知决策的过程,从数据维度上看,我们可以把语言智能的输出结果看做是1维数据,把图像和视频看做2维和2.5维数据,那么3维空间+时间就是4维数据,这也是世界模型和空间智能探索的对象。空间智能是除了语言智能之外,通往通用智能的第二条技术路径,两者的目标是一致的,都是希望把AI从虚拟世界扩展到物理世界,做法有些不同,语言模型更多对内,从思考出发,到行动;世界模型更多对外,从交互出发,到行动。
以Sora视频生成为例子,很多人在讨论Sora是不是一个世界模拟器,朱政博士认为,目标是对的,但是技术路线可能不够高效。为什么这么说,因为从文本或者图像生成视频其实是一件非常难的事情,但是如果显式地利用4D世界模型进行建模的话,可以在很大程度上把问题变得简单,更快在物理空间和虚拟空间中落地。
世界模型
朱政博士从世界模型的具体定义出发,谈及到以人为启发的智能学习方式,并指出构建世界模型的目的是从数据中学习到世界的运转规律,掌握知识。目前对世界模型的研究集中在视频生成、自动驾驶、智能体和通用机器人三个领域,分别有一些基础任务和应用场景。现在无论是数字世界的语言模型和视频生成模型,还是物理世界的自动驾驶和机器人,所有通用智能问题都在走向端到端,核心均是世界模型,包括闭环模拟器和高质量4D闭环数据两部分。过去的做法是依赖互联网数据、仿真数据、实采数据和机器人遥操数据,缺点比较明显,缺乏真实性、成本高、Corner case少、效率低;如果用世界模型这种全新的方式作为数据来源的话,可以总结为4个字:多快好省,多就是可以规模化生成,快就是不受限制,好指的是生成的数据价值密度高,省就是成本低。
极佳科技世界模型的研究和应用
朱政博士系统性地介绍了极佳科技DriveDreamer世界模型系列在自动驾驶数据生成和闭环仿真中的探索和应用。
DriveDreamer由极佳科技研究人员在2023年9月提出,是首个真实自动驾驶场景驱动的世界模型,相关的论文入选了PaperDigest最有影响力ECCV论文之一;DriveDreamer可以生成丰富多样的驾驶场景视频,包括不同的驾驶背景、天气、时间等,也可以给定相同的初始帧,根据改变的输入速度和角度,生成出不同的未来视频,还可以根据历史的驾驶动作以及初始的图像观测,预测合理的未来驾驶动作。
DriveDreamer-2进一步引入了大语言模型,可以根据用户的自然语言输入生成对应场景的自动驾驶视频,并在下游感知任务上大幅度提升相关指标。
世界模型除了可以生成多样化的视频训练数据之外,还可以应用到闭环仿真中。闭环仿真里面很重要的一件事情是对场景进行重建,重建一般需要多视角的数据,但是自动驾驶数据集都只有前进的单一视角数据,可以利用世界模型的能力,生成新视角的数据来辅助重建。具体来说,在DriveDreamer4D这项工作里,极佳科技的研究人员从原始轨迹出发,进行速度和车道的变化,再映射出来新的结构化信息,经由视频生成世界模型可以得到新轨迹的数据,进而和原始数据一起优化重建模型。
世界模型辅助场景重建的另外一条实现路径是先进行重建再生成。极佳科技在另一篇工作ReconDreamer中,先利用重建模型对动态驾驶场景进行建模,然后在原轨迹的基础上逐步采样新轨迹渲染得到视频,利用世界模型进行修复,修复后的数据以一定的比例加入重建的优化过程中。实验结果表明,DriveDreamer4D和ReconDreamer可以极大程度地提升变道、平移等新轨迹下的渲染质量。
未来展望
最后,朱政博士对世界模型和空间智能在2025年的发展趋势进行了预测和展望。世界模型即将从自动驾驶扩展到更为宽广的具身智能领域,并将拥有更高程度的逻辑推理与决策能力,非常有希望突破传统的任务界限,接棒成为多模态大模型发展的下一站。空间智能将和语言模型一样,重塑机器人、人机交互、影视游戏、元宇宙等行业。
嘉宾介绍:
朱政博士
极佳科技联合创始人、首席科学家。2019年至2021年在清华大学自动化系从事博士后研究,2019年博士毕业于中国科学院自动化研究所。在TPAMI、CVPR、ICCV、ECCV、NeurIPS等顶级期刊和会议上发表论文50余篇,文章总引用13000余次(Google Citations),2022、2023、2024连续三年入选斯坦福大学评选的全球前2%顶尖科学家榜单。
代表作SiamRPN和DaSiamRPN是深度学习时代最具影响力的目标跟踪算法之一,开辟了孪生网络目标跟踪的研究方向,分别被引用3100余次和1600余次,并被集成进OpenCV;BEVDet是BEV感知领域的代表性算法,被多家车企和自动驾驶公司3D感知方案所采用,累计被引用600余次;WebFace260M是全球最大的人脸识别数据集,被400余家科研机构申请使用,DriveDreamer世界模型入选ECCV最具影响力论文榜单。获得过COCO、VOT等顶级视觉竞赛冠军,并在KITTI、nuScenes、NIST-FRVT等榜单上排名第一,在ICCV 2021上组织戴口罩人脸识别比赛,将近500支队伍参赛并完成超过10000次提交。担任权威人脸识别国际会议IEEE FG 2023领域主席。

我要收藏
点个赞吧
转发分享

微信"扫一扫",分享转发
咨询详情:如需咨询文中涉及的相关产品或解决方案详情,请加微信:ZiDongHuaX 。
微信联盟:人工智能微信群、具身智能微信群、机器人微信群、语言智能微信群、空间智能微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 解密英特尔酷睿处理器(系列1)



微信联盟:人工智能微信群、具身智能微信群、机器人微信群、语言智能微信群、空间智能微信群,各细分行业微信群:点击这里进入。
鸿达安视:水文水利在线监测仪器、智慧农业在线监测仪器 解密英特尔酷睿处理器(系列1)










评论排行